Paper 7: Mastering Complex Control in MOBA Games with Deep Reinforcement Learning (Honour of Kings)
Slides
Abstract
-
We study the reinforcement learning problem of complex action control in the Multi-player Online Battle Arena (MOBA) 1v1 games.
-
This problem involves far more complicated state and action spaces than those of traditional 1v1 games, such as Go and Atari series, which makes it very difficult to search any policies with human-level performance.
-
we present a deep reinforcement learning framework to tackle this problem from the perspectives of both system and algorithm.
-
Our system is of low coupling and high scalability, which enables efficient explorations at large scale.
-
Our algorithm includes several novel strategies, including control dependency decoupling, action mask, target attention, and dual-clip PPO, with which our proposed actor-critic network can be effectively trained in our system.
-
1 Introduction
In this paper, we move on to one type of 1v1 games that has the next level of complexity, i.e., the MOBA 1v1 games.
-
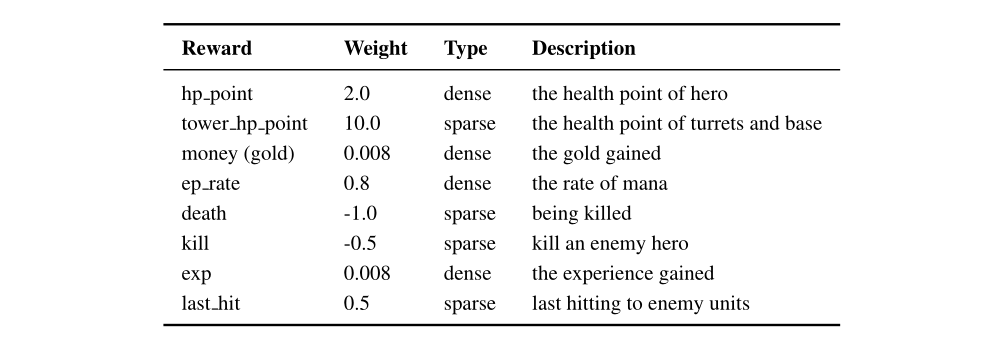
Compared with traditional 1v1 games, MOBA 1v1 games have
far more complicated environments and controls. Take the Honor of Kings as an example, the magnitude of states and actions involved can reach to 10^600 and 10^18000, while these in Go are 10^170 and 10^360, illustrated in the following table.
-
Besides, the complexity of MOBA 1v1 also comes from the
playing mechanism. To win a game, in the partially observable environment, agents must learn to plan, attack, defend, control skill combos, induce, and deceive the opponents. Apart from the player’s and the opponent’s agent, there exists many more game units, e.g., creeps and turrets. This creates challenge to the target selection which requires delicate sequences of decision making and corresponding action controls. -
Furthermore, different heroes in a MOBA game have very
different playing methods. The action control can completely change from hero to hero, which calls for robust and unified modeling. -
Last but not least, there
lacks high-quality human game datafor MOBA 1v1 which makes supervised learning unfeasible, because players generally use the 1v1 mode to practice heroes, while the MOBA 5v5 mode is used for formal matches in mainstream MOBA games, like Dota and Honor of Kings.
To handle these challenges, we design a deep reinforcement learning framework, together with a set of algorithm-level innovations, to enable efficient explorations at massive scale for multi-agent competitive environments like MOBA 1v1 games.
We design a neural network architecture including the encoding of multi-modal inputs, the decoupling of intercorrelations in controls, exploration pruning mechanism, and attack attention, to consider the everchanging game situations in MOBA 1v1 games.
Our contributions are as follows:
-
We present a systematic and thorough study on building AI for playing MOBA 1v1 games, which require highly complex action control of agents.
-
On system aspect, we develop a deep reinforcement learning framework which provides
scalable and off-policy training. -
On algorithm aspect, we develop an actor-critic neural network for modeling MOBA action controls. Our network optimizes with a multi-label proximal policy algorithm (PPO) objective, and is featured with the decoupling of control dependency, an attention mechanism for target selection, action mask for efficient exploration, LSTM for learning skill combos, and an improved version of PPO, called dual-clip PPO, for ensured training convergence.
-
-
Extensive experiments show that the trained AI agent can defeat top professional human players on different hero types, tested on the 1v1 mode of Honor of Kings.
3 System Design
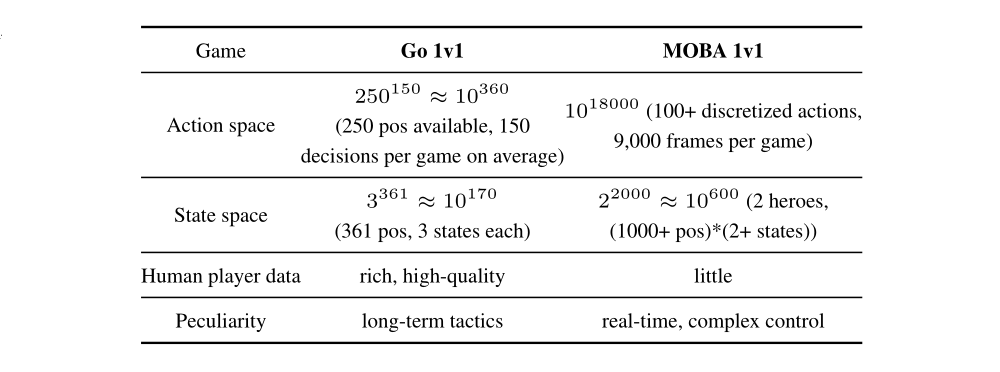
Considering the fact that complex agent control problems can introduce high variance of stochastic gradients, e.g. the MOBA 1v1 games, large batch size is necessary to speed up the training. Thus, we design a scalable and loosely-coupled system architecture to construct the utility of data parallelism. Specifically, our architecture consists of four modules as shown in the figure,
Overview of our System Design
-
Reinforcement Learning Learner: The RL Learner is a distributed training environment.-
To accelerate policy update using large batch sizes, multiple RL Learners are integrated to parallelly fetch data from the same number of Memory Pools.
-
The gradients in the RL learners are averaged through the ring allreduce algorithm.
-
To reduce IO cost, RL Learners communicate with Memory Pools using shared memory instead of socket, which can deliver 2-3 times of speed boosting.
-
The trained models from the RL Learners are rapidly synchronized to AI Servers in a peer-to-peer(点对点)manner.
-
-
Artificial Intelligence (AI) Server: AI Server implements how the AI model interacts with the environment.-
AI server generates episodes via self-play with mirrored policies. The opponent policy sampling is similar to (Bansal et al. 2017).
-
Based on the features extracted from game state, hero action is predicted using Boltzman exploration, i.e., sampling based on softmax distribution.
-
The sampled action is then forwarded to the game core for execution. After execution, the game core returns the corresponding reward value and the next state continuously.
-
In use, one AI Server will bind one CPU core. Because the game logic deduction runs on CPUs, we also run the model inference on CPUs to save the IO cost. In order to generate episodes efficiently, we build a CPU version of the fast inference library FeatherCNN, which can automatically convert AI models trained from mainstream tools like Tensorflow and Caffe, to a customized format for inference.
-
-
Dispatch Module: The Dispatch Module is a station for sample collection, compression and transmission.Dispatch Module is bounded with several AI Servers on the same machine. It is a server that collects data samples from AI Servers, consisting of reward, feature, action probabilities, etc. These samples are firstly compressed and packed, and then send to Memory Pools. -
Memory Pool: The Memory Pool is the data storage module, which provides training instances for the RL Learner.The Memory Pool is also a server. Its internals are implemented as a memory efficient circular queue for data storage. It supports samples of varied lengths, and data sampling based on the generated time.
These modules are decoupled and can be flexibly configured, so that our researchers can focus on the algorithm design and the logic of the environment. Such a system design is also applicable to other multi-agent competitive problems.
In our system, the experiences generation is decoupled from the parameters learning. This flexible mechanism makes AI Servers and RL learners scalable with high throughput. To avoid the bottleneck of communication cost between learners and actors, our trained models are synchronized to AI Servers via peer-to-peer from our master RL Learner. To smooth data storage and transmission, we design two mediators, i.e., the Dispatch Server and the Memory Pool Server. In practice, we can scale to millions of CPU cores and thousands of GPUs effortlessly. Note that such design differs from existing system designs like IMPALA. In IMPALA, parameters are distributed across the learners, and actors retrieve the parameters from all the learners in parallel.
4 Algorithm Design
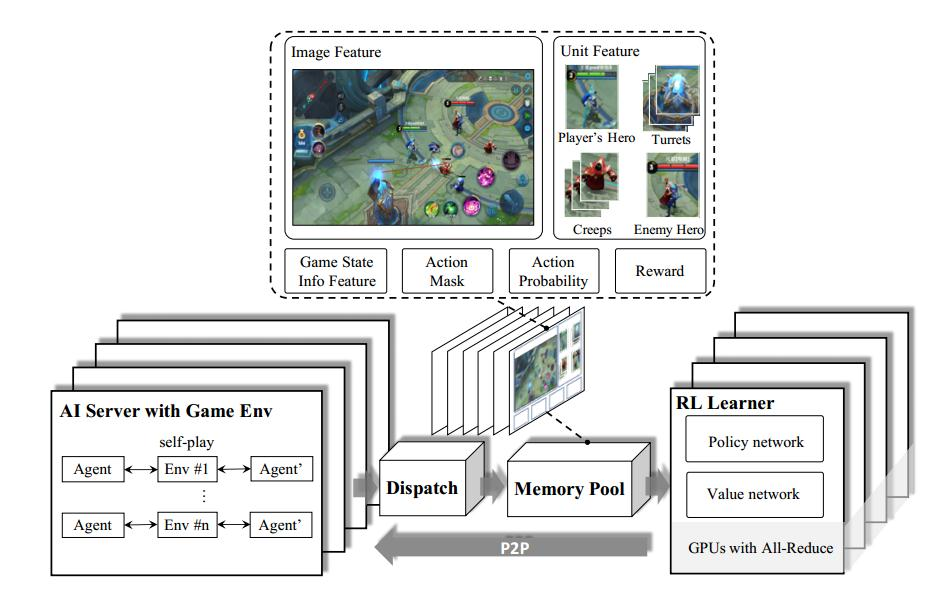
In the RL Learner, an actor-critic network is implemented to model the action control dependencies in MOBA 1v1 games. The figure illustrates this network, the state and actions.
To train this network efficiently and effectively, several novel strategies are proposed.
-
First, the
target attention mechanismis designed in this network to help with the target selection in MOBA combats. -
Second,
LSTMsare leveraged for the hero to learn the skill combos which are critical to create severe and instant damage. -
Third, the
decoupling of control dependenciesis conducted to form a multi-label proximal policy optimization (PPO) objective. -
Forth, a game-knowledge-based pruning method, called
action maskis developed to guide explorations during the reinforcement process. -
Finally, a
dual-clipped version of the PPOalgorithm is proposed to guarantee convergence with large and deviated batches.
The details of our network:
-
The target unit t of action a is predicted by a target attention mechanism over every unit. This mechanism treats a FC output of hLSTM as the query, the stack of all unit encodings as the keys hkeys, and calculate the target attention as the following figure, where
p(t|a) is the attention distribution over units and the dimension of p(t|a) is the number of units in the state.
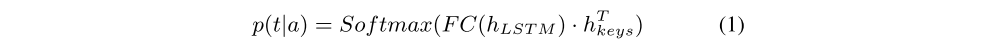
-
It’s very hard to explicitly model the intercorrelations among different labels in one action of MOBA games in the multi-label policy network. To solve this issue, we
treat each label in an action independently to decouple their intercorrelations, i.e., the decoupling of control dependencies. Before decoupling the inter-correlations, the PPO objective without clipping is:
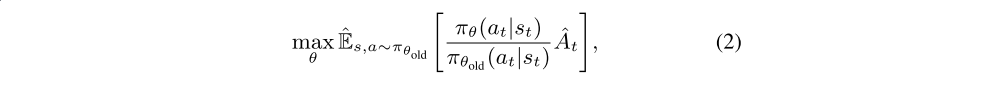
-
Suppose
each action a = (a0, . . . , aNa−1), then the objective after action decoupling becomes the Equation(3). This decoupled objective brings two advantages:-
First, it simplifies the policy structure. Specifically, the policy network can be defined without considering the intercorrelations as this dependency can be post-processed.
-
Second, it increases the diversity of actions. As each component has its independent own channel of value output, the actions can be significantly diversified, thus inducing more explorations during training.
-
Furthermore, to force diversity of exploration, we randomize the positions of both agents during training at the beginning of the game.
-
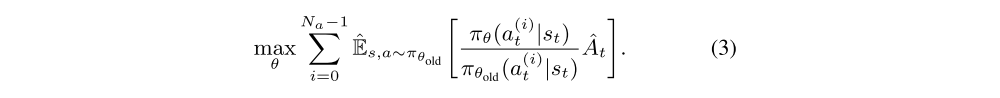
-
The action decoupling further increases the complexity of policy training, while it is originally very high due to the vast action and state spaces in MOBA 1v1 games. To improve the training efficiency, an
action mask is proposed to incorporate the correlations between action elements at the final output layers of the policy based on prior knowledge of experienced human player, which helps prune the exploration of RL. Specifically, our action mask helps eliminate several unreasonable aspects:-
Physically forbidden areas on map
-
Skill or attack availability
-
Being controlled by enemy hero skill or equipment effects
-
Hero-/item-specific restrictions
-
Dual-clip PPO: Let rt(θ) denote the probability ratio. Because the ratio rt(θ) can be extremely large, maximization of the RL objective may lead to an excessively large policy deviation(偏差). To alleviate this issue, the standard PPO algorithm involves a ratio clip as follows:
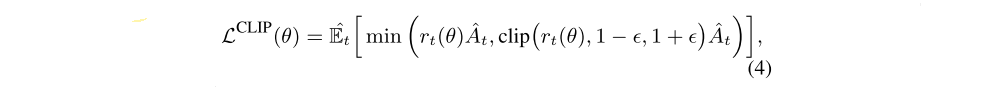
to penalize extreme changes to the policy.
However, in large-scale off-policy training environments like our framework, the trajectories are sampled from various sources of policies, which may differ considerably from the current policy πθ. In such situations, the standard PPO will fail to work with such deviations since it was originally proposed for on-policy.
For example, If the ratio rt(θ) is a huge number, when Aˆt<0, such a large ratio rt(θ) will introduce a big and unbounded variance since rt(θ)ˆAt is much less than 0. As a result, even using the objective of PPO, the new policy deviates significantly from the old policy, which makes it very difficult to insure the policy convergence. We thus propose a dual-clipped PPO algorithm to support large-scale distributed training, which further clip the ratio rt(θ) with a lower bound of the value rt(θ)ˆAt, illustrated in the figure: (a) Standard PPO ; Our Proposed Dual-clip PPO.
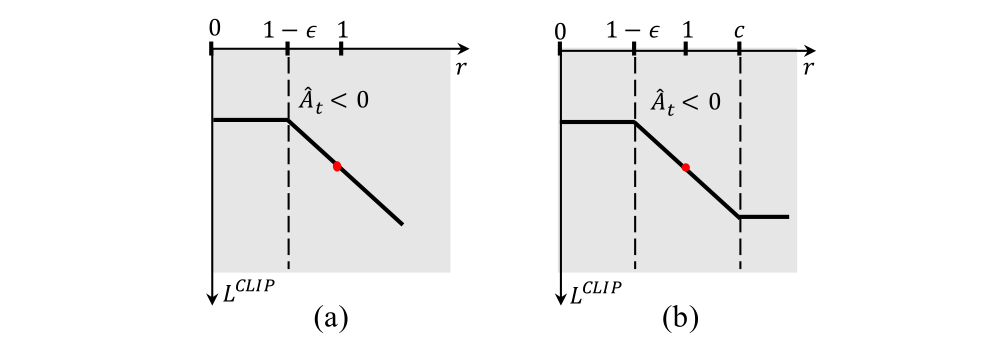
When Aˆt<0, the new objective of our dual-clipped PPO is:
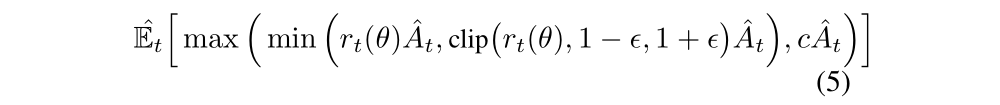
where c>1 is a constant indicating the lower bound.
5 Experiments
We use Adam optimizer with initial learning rate 0.0001. In the dual-clipped PPO, the two clipping hyperparameters ε and c are set as 0.2 and 3, respectively. The discount factor is set as 0.997. For the case of Honor of Kings, this discount is valuing future rewards with a half-life of about 46 seconds. We use generalized advantage estimation (GAE) for reward calculation, and we set λ = 0.95 in GAE to reduce the variance caused by delayed effects.
Other details of the experiment will not be detailed here.
7 Appendix
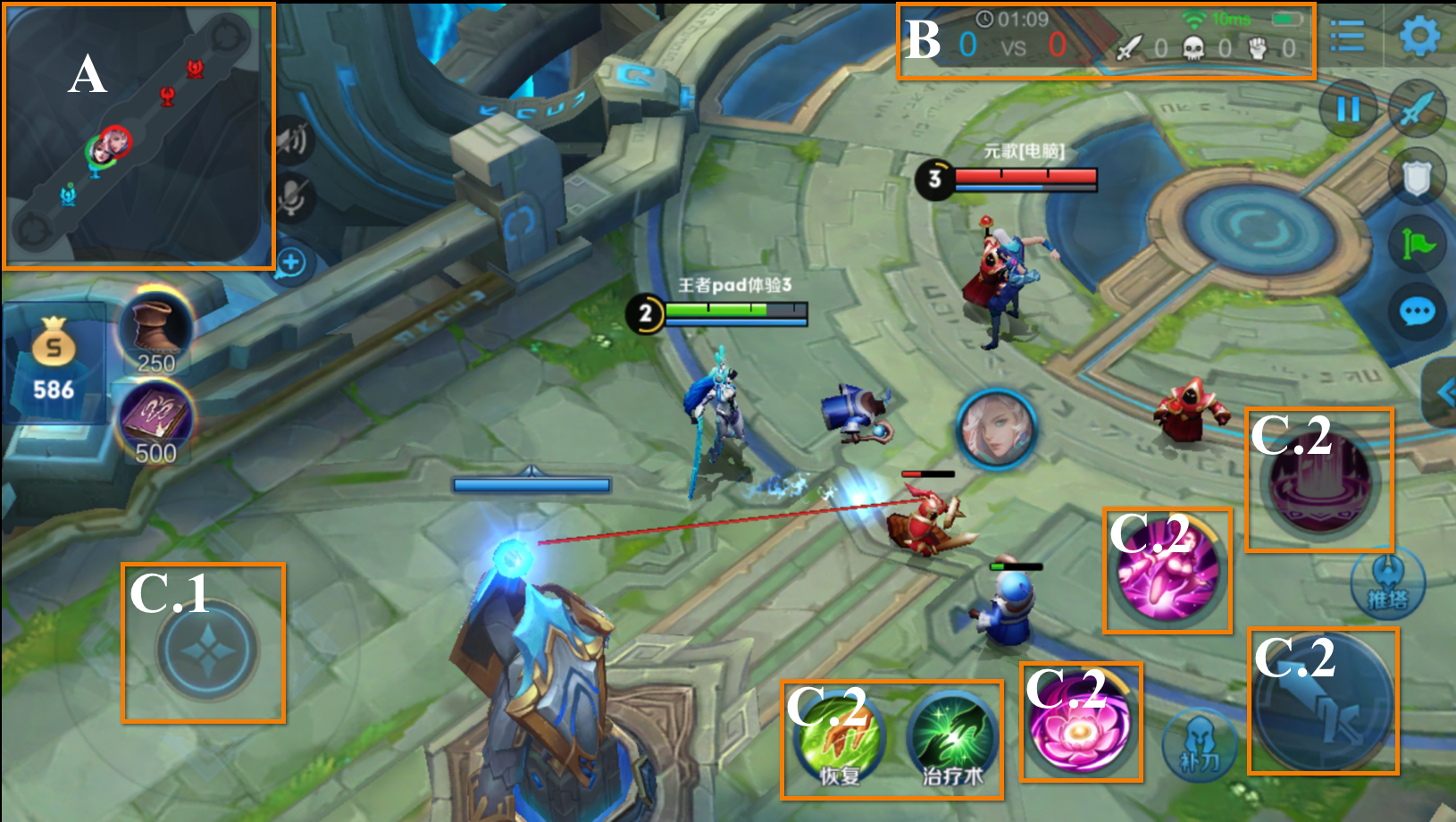
Game UI of Honor of Kings 1v1. In the main screen, there are four sub-parts: mini-map (A) on the top-left, dashboard (B) on the top-right, movement controller (C.1) on the bottom-left, and ability controller (C.2) on the bottom-right, as highlighted in each box.
The reward design is inspired by OpenAI Five’s Dota reward (OpenAI 2018). The reward is zero-sum, i.e., one’s mean reward is subtracted from that of the opponent(对手). Our framework allows on-the-fly reward analysis during training. A case of the DiaoChan hero is shown as below.