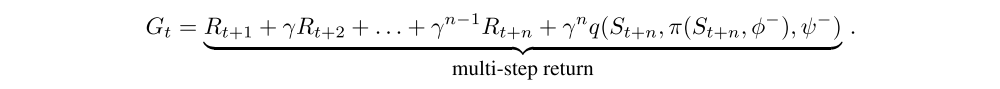Paper 17: Distributed Prioritized Experience Replay (Ape-X)
Abstract
-
We propose a distributed architecture for Deep-RL at scale, that enables agents to learn effectively from orders of magnitude more data than previously possible.
-
The algorithm decouples acting from learning.
-
The architecture relies on prioritized experience replay to focus only on the most significant data generated by the actors.
1 Introduction
In this paper we describe an approach to scaling up Deep-RL by generating more data and selecting from it in a prioritized fashion. Standard approaches to distributed training of neural networks focus on parallelizing the computation of gradients, to more rapidly optimize the parameters. In contrast, we distribute the generation and selection of experience data, and find that this alone suffices to improve results. This is complementary to distributing gradient computation, and the two approaches can be combined, but in this work we focus purely on data-generation.
We use this distributed architecture to scale up variants of DQN and DDPG, and we evaluate these on the Arcade Learning Environment benchmark, and on a range of continuous control tasks.
We empirically investigate the scalability of our framework, analyzing how prioritization affects performance as we increase the number of data-generating workers. Our experiments include an analysis of factors such as the replay capacity, the recency of the experience, and the use of different data-generating policies for different workers. Finally, we discuss implications for Deep-RL agents that may apply beyond our distributed framework.
2 Background
-
Distributed Stochastic Gradient Descent
Parallelize the computation of the gradients used to update their parameters. The resulting parameter updates may be applied synchronously or asynchronously.
-
Distributed Importance Sampling
A complementary family of techniques for speeding up training is based on variance reduction by means of importance sampling. Sampling non-uniformly from a dataset and weighting updates according to the sampling probability in order to counteract(抵消)the bias thereby introduced can increase the speed of convergence by reducing the variance of the gradients. One way of doing this is to select samples with probability proportional to the L2 norm of the corresponding gradients.
-
Prioritized Experience Replay
Prioritized experience replay extends classic prioritized sweeping ideas to work with DNN function approximators. The approach is strongly related to the importance sampling techniques, but using a more general class of biased sampling procedures that focus learning on the most ‘surprising’ experiences. Biased sampling can be particularly helpful in RL, since the reward signal may be sparse and the data distribution depends on the agent’s policy.
3 Our Contribution: Distributed Prioritized Experience Replay
In this paper we extend prioritized experience replay to the distributed setting and show that this is a highly scalable approach to Deep RL. We introduce a few key modifications that enable this scalability, and we refer to our approach as Ape-X.
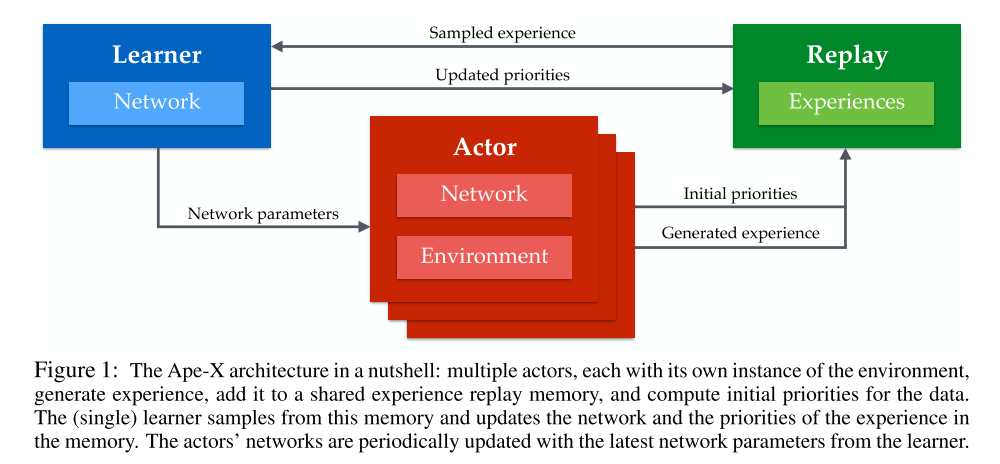
In principle, both acting and learning may be distributed across multiple workers. In our experiments, hundreds of actors run on CPUs to generate data, and a single learner running on a GPU samples the most useful experiences (Figure 1).
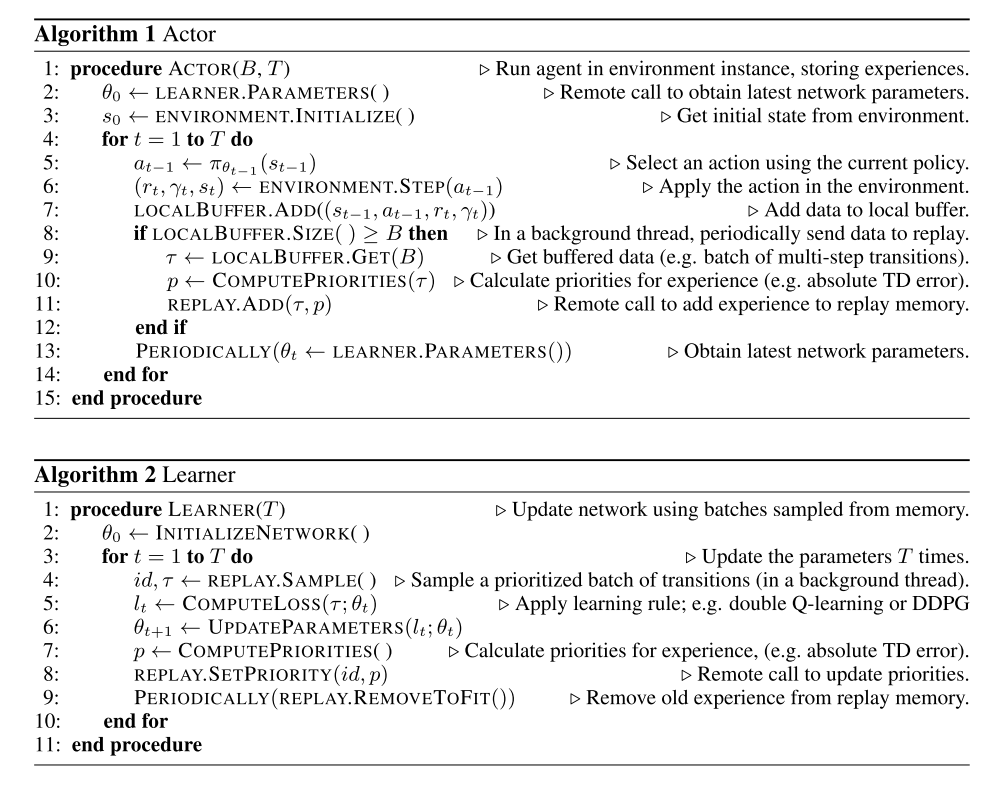
Pseudocode for the actors and learners is shown in Algorithms 1 and 2.
We use a shared, centralized replay memory, and instead of sampling uniformly, we prioritize, to sample the most useful data more often. Since priorities are shared, high priority data discovered by any actor can benefit the whole system. Priorities can be defined in various ways, depending on the learning algorithm; two instances are described in the next sections.
We take advantage of the computation the actors in Ape-X are already doing to evaluate their local copies of the policy, by making them also compute suitable priorities for new transitions online. This ensures that data entering the replay has more accurate priorities, at no extra cost.
Sharing experiences has certain advantages compared to sharing gradients. Low latency communication is not as important as in distributed SGD, because experience data becomes outdated less rapidly than gradients, provided the learning algorithm is robust to off-policy data. Across the system, we take advantage of this by batching all communications with the centralized replay, increasing the efficiency and throughput at the cost of some latency. With this approach it is even possible for actors and learners to run in different data-centers without limiting performance.
Finally, by learning off-policy, we can further take advantage of Ape-X’s ability to combine data from many distributed actors, by giving the different actors different exploration policies, broadening the diversity of the experience they jointly encounter. As we will see in the results, this can be sufficient to make progress on difficult exploration problems.
3.1 Ape-X DQN
The general framework we have described may be combined with different learning algorithms. First, we combined it with a variant of DQN with some of the components of Rainbow. More specifically, we used double Q-learning with multi-step bootstrap targets as the learning algorithm, and a dueling network architecture as the function approximator q(·, ·, θ).
This results in computing for all elements in the batch the loss
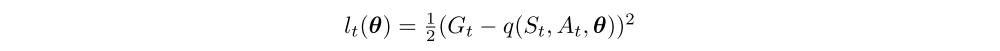
with
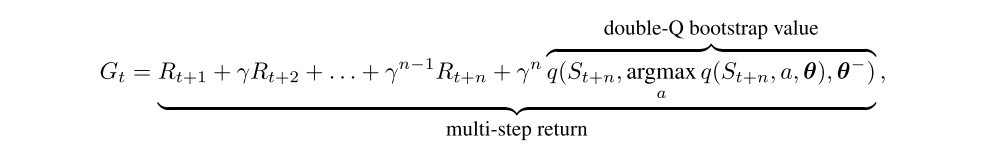
In principle, Q-learning variants are off-policy methods, so we are free to choose the policies we use to generate data. However, in practice, the choice of behaviour policy does affect both exploration and the quality of function approximation. Furthermore, we are using a multi-step return with no off-policy correction, which in theory could adversely affect the value estimation. Nonetheless, in Ape-X DQN, each actor executes a different policy, and this allows experience to be generated from a variety of strategies, relying on the prioritization mechanism to pick out the most effective experiences. In our experiments, the actors use ε-greedy policies with different values of ε. Low ε policies allow exploring deeper in the environment, while high ε policies prevent over-specialization.
3.2 Ape-X DPG
To test the generality of the framework we also combined it with a continuous-action policy gradient system based on DDPG and tested it on continuous control tasks from the DeepMind Control Suite.
The Ape-X DPG setup is similar to Ape-X DQN, but the actor’s policy is now represented explicitly by a separate policy network, in addition to the Q-network. The two networks are optimized separately, by minimizing different losses on the sampled experience. We denote the policy and Q-network parameters by φ and ψ respectively, and adopt the same convention as above to denote target networks. The Q-network outputs an action-value estimate q(s, a, ψ) for a given state s, and multi-dimensional action a ∈ Rm. It is updated using temporal-difference learning with a multi-step bootstrap target. The Q-network loss can be written as
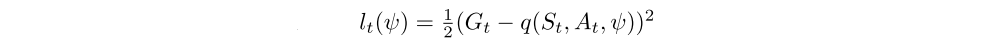
where