Paper 19: Deep Recurrent Q-Learning for Partially Observable MDPs (DRQN)
Abstract
-
DRL controllers have limited memory and rely on being able to perceive the complete game screen at each decision point.
-
This article investigates the effects of adding recurrency to a DQN by replacing the first post-convolutional fully-connected layer with a recurrent LSTM.
-
The resulting DRQN, although capable of seeing only a single frame at each timestep, successfully integrates information through time.
-
Given the same length of history, recurrency is a viable alternative to stacking a history of frames in the DQN’s input layer and while recurrency confers no systematic advantage when learning to play the game, the recurrent net can better adapt at evaluation time if the quality of observations changes.
1 Introduction
DQN are limited in the sense that they learn a mapping from a limited number of past states, or game screens in the case of Atari 2600. Thus DQN will be unable to master games that require the player to remember events more distant than four screens in the past. Put differently, any game that requires a memory of more than four frames will appear non-Markovian because the future game states (and rewards) depend on more than just DQN’s current input. Instead of a Markov Decision Process (MDP), the game becomes a Partially-Observable Markov Decision Process (POMDP).
We observe that DQN’s performance declines when given incomplete state observations and hypothesize that DQN may be modified to better deal with POMDPs by leveraging advances in RNNs. Therefore we introduce the DRQN, a combination of a LSTM and a DQN. Crucially, we demonstrate that DRQN is capable of handing partial observability, and that when trained with full observations and evaluated with partial observations, DRQN better handles the loss of information than does DQN. Thus, recurrency confers benefits as the quality of observations degrades.
Our experiments show that adding recurrency to Deep Q-Learning allows the Q-network network to better estimate the underlying system state, narrowing the gap between Q(o, a|θ) and Q(s, a|θ). Stated differently, recurrent deep Q-networks can better approximate actual Q-values from sequences of observations, leading to better policies in partially observed environments.
2 DRQN Architecture
To isolate the effects of recurrency, we minimally modify the architecture of DQN, replacing only its first fully connected layer with a recurrent LSTM layer of the same size. Depicted in the following figure, the architecture of DRQN takes a single 84 × 84 preprocessed image. This image is processed by three convolutional layers and the outputs are fed to the fully connected LSTM layer. Finally, a linear layer outputs a Q-Value for each action. During training, the parameters for both the convolutional and recurrent portions of the network are learned jointly from scratch.
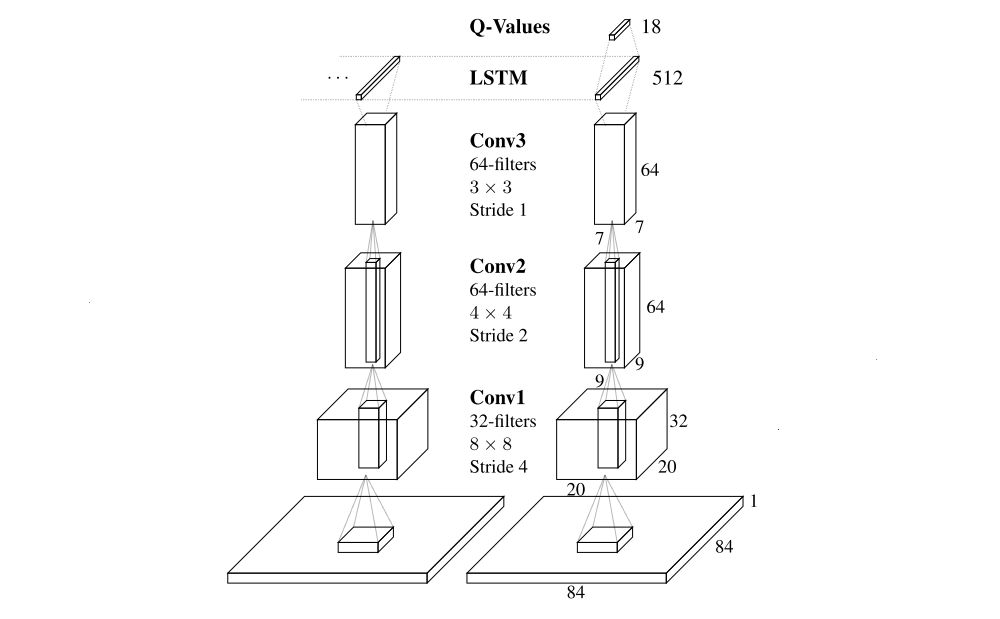
DRQN convolves three times over a single-channel image of the game screen.
3 Stable Recurrent Updates
Updating a recurrent, convolutional network requires each backward pass to contain many time-steps of game screens and target values. Additionally, the LSTM’s initial hidden state may either be zeroed or carried forward from its previous values. We consider two types of updates:
-
Bootstrapped Sequential Updates
Episodes are selected randomly from the replay memory and updates begin at the beginning of the episode and proceed forward through time to the conclusion of the episode. The targets at each time-step are generated from the target Q-network, Qˆ. The RNN’s hidden state is carried forward throughout the episode.
-
Bootstrapped Random Updates