Paper 21: SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference
Github: http://github.com/google-research/seed_rl.
Abstract
-
We present a modern scalable reinforcement learning agent called SEED (Scalable, Efficient Deep-RL).
-
By effectively utilizing modern accelerators, we show that it is not only possible to train on millions of frames per second but also to lower the cost of experiments compared to current methods.
-
We achieve this with a simple architecture that features centralized inference and an optimized communication layer.
-
SEED adopts two state of the art distributed algorithms, IMPALA/V-trace (policy gradients) and R2D2 (Q-learning), and is evaluated on Atari-57, DeepMind Lab and Google Research Football.
1 Introduction
In the very recent history, focus on massive scale has been key to solve a number of complicated games such as AlphaGo, Dota and StarCraft 2.
The sheer amount of environment data needed to solve tasks trivial to humans, makes distributed machine learning unavoidable for fast experiment turnaround time. RL is inherently comprised of heterogeneous tasks: running environments, model inference, model training, replay buffer, etc. and current state-of-the-art distributed algorithms do not efficiently use compute resources for the tasks. The amount of data and inefficient use of resources makes experiments unreasonably expensive. The two main challenges addressed in this paper are scaling of RL and optimizing the use of modern accelerators, CPUs and other resources.
We introduce SEED (Scalable, Efficient, Deep-RL), a modern RL agent that scales well, is flexible and efficiently utilizes available resources. It is a distributed agent where model inference is done centrally combined with fast streaming RPCs to reduce the overhead of inference calls. We show that with simple methods, one can achieve state-of-the-art results faster on a number of tasks. For optimal performance, we use TPUs and TensorFlow 2 to simplify the implementation. The cost of running SEED is analyzed against IMPALA which is a commonly used state-of-the-art distributed RL algorithm. We show cost reductions of up to 80% while being significantly faster. When scaling SEED to many accelerators, it can train on millions of frames per second.
2 Related Work
-
For scaling value-based methods: Asynchronous SGD; Ape-X; R2D2
-
For scaling policy gradients methods: A3C; GA3C; IMPALA; OpenAI Rapid
-
A third class of algorithms is evolutionary algorithms.
-
Libraries and frameworks: ELF; Dopamine; TF-Agents; rlpyt; TorchBeast;
RLLibprovides a number of composable distributed components and a communication abstraction with a number of algorithm implementations such as IMPALA and Ape-X.
SEED is closest related to IMPALA, but has a number of key differences that combine the benefits of single-machine training with a scalable architecture. Inference is moved to the learner but environments run remotely. This is combined with a fast communication layer to mitigate latency issues from the increased number of remote calls. The result is significantly faster training at reduced costs by as much as 80% for the scenarios we consider. Along with a policy gradients (V-trace) implementation we also provide an implementation of state of the art Q-learning (R2D2). In the work we use TPUs but in principle, any modern accelerator could be used in their place. TPUs are particularly well-suited given they high throughput for machine learning applications and the scalability. Up to 2048 cores are connected with a fast interconnect providing 100+ petaflops of compute.
3 Architecture
Before introducing the architecture of SEED, we first analyze the generic actor-learner architecture used by IMPALA, which is also used in various forms in Ape-X, OpenAI Rapid and others. An overview of the architecture is shown below.
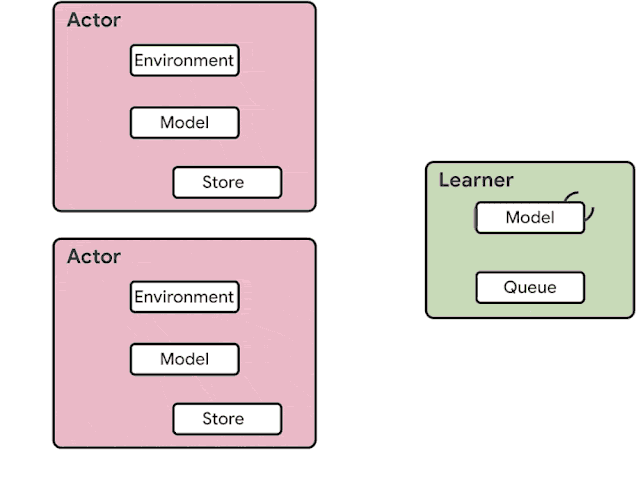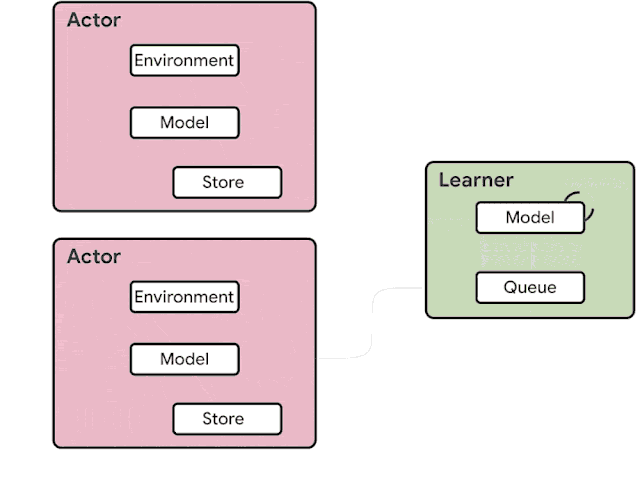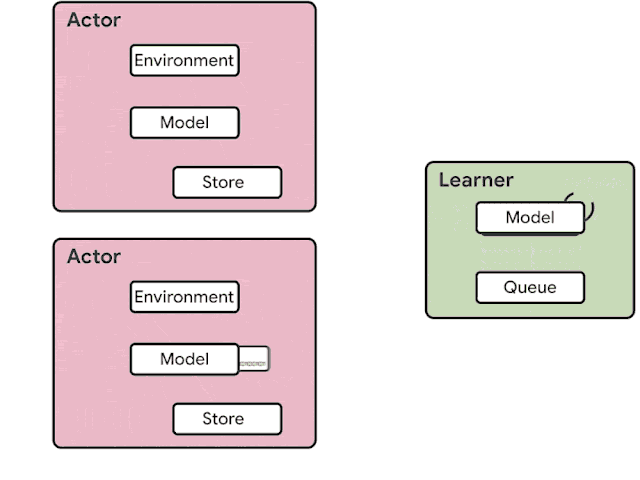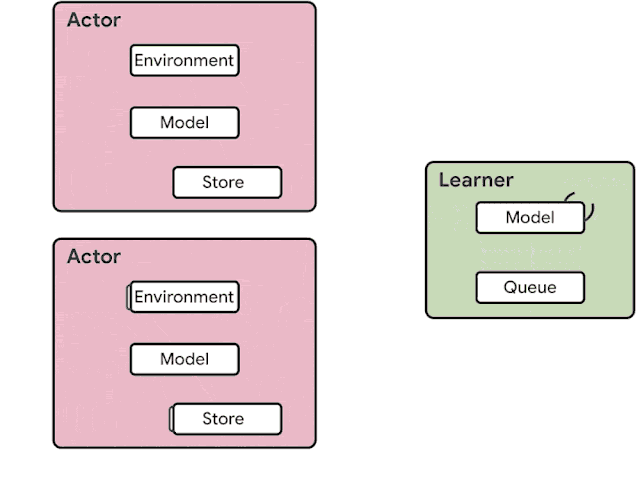
A large number of actors repeatedly read model parameters from the learner (or parameter servers). Each actor then proceeds the local model to sample actions and generate a full trajectory of observations, actions, policy logits/Q-values. Finally, this trajectory along with recurrent state is transferred to a shared queue or replay buffer. Asynchronously, the learner reads batches of trajectories from the queue/replay buffer and optimizes the model.
There are a number of reasons for why this architecture falls short:
-
Using CPUs for neural network inference: The actor machines are usually CPU-based (occasionally GPU-based for expensive environments). CPUs are known to be computationally inefficient for neural networks. When the computational needs of a model increase, the time spent on inference starts to outweigh the environment step computation. The solution is to increase the number of actors which increases the cost and affects convergence. -
Inefficient resource utilization: Actors alternate between two tasks: environment steps and inference steps. The compute requirements for the two tasks are often not similar which leads to poor utilization or slow actors. E.g. some environments are inherently single-threading while neural networks are easily parallelizable. -
Bandwidth requirements: Model parameters, recurrent state and observations are transferred between actors and learners. Relatively to model parameters, the size of the observation trajectory often only accounts for a few percents. Furthermore, memory-based models send large states, increase bandwidth requirements.
While single-machine approaches such as GA3C and single-machine IMPALA avoid using CPU for inference (1) and do not have network bandwidth requirements (3), they are restricted by resource usage (2) and the scale required for many types of environments.
The architecture used in SEED (shown below) solves the problems mentioned above. Inference and trajectory accumulation is moved to the learner which makes it conceptually a single-machine setup with remote environments (besides handling failures). Moving the logic effectively makes the actors a small loop around the environments. For every single environment step, the observations are sent to the learner, which runs the inference and sends actions back to the actors. This introduces a new problem: 4. Latency.
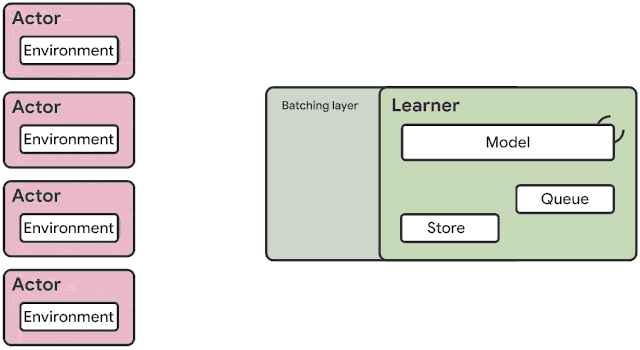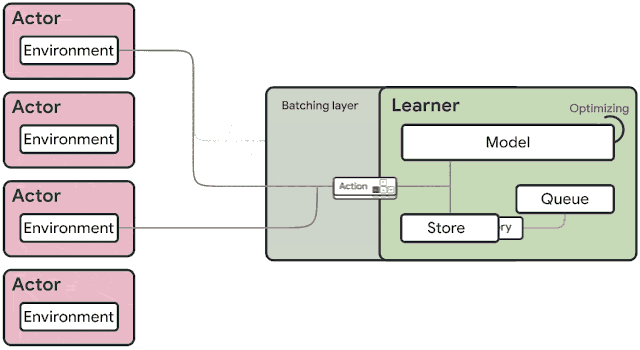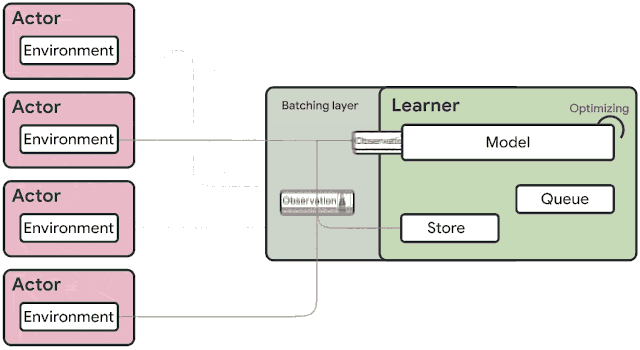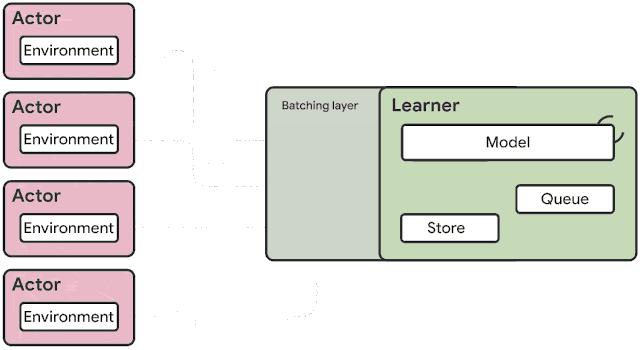
To minimize latency, we created a simple framework that uses gRPC - a high performance RPC library. Specifically, we employ streaming RPCs where the connection from actor to learner is kept open and metadata sent only once. Furthermore, the framework includes a batching module that efficiently batches multiple actor inference calls together. In cases where actors can fit on the same machine as learners, gRPC uses unix domain sockets and thus reduces latency, CPU and syscall overhead. Overall, the end-to-end latency, including network and inference, is faster for a number of the models we consider.
The IMPALA and SEED architectures differ in that for SEED, at any point in time, only one copy of the model exists whereas for distributed IMPALA each actor has its own copy. This changes the way the trajectories are off-policy. In IMPALA, an actor uses the same policy πθt for an entire trajectory.
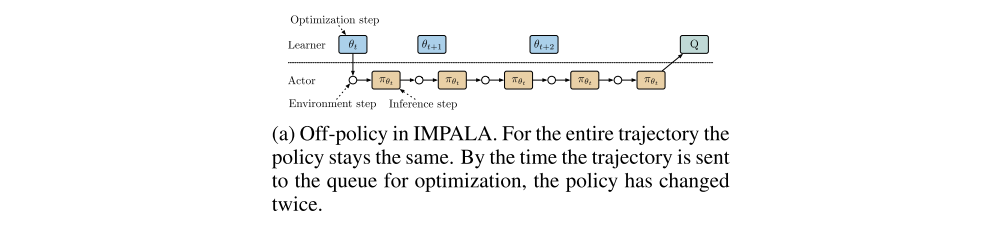
But for SEED, the policy during an unroll of a trajectory may change multiple times with later steps using more recent policies closer to the one used at optimization time.
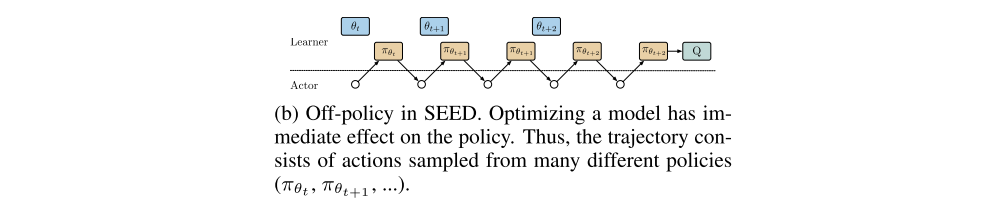
A detailed view of the learner in the SEED architecture is shown as below. Three types of threads are running:
-
Inference
-
Data prefetching(预先载入)
-
Training.
Inference threads receive a batch of observations, rewards and episode termination flags. They load the recurrent states and send the data to the inference TPU core. The sampled actions and new recurrent states are received, and the actions are sent back to the actors while the latest recurrent states are stored. When a trajectory is fully unrolled it is added to a FIFO queue or replay buffer and later sampled by data prefetching threads. Finally, the trajectories are pushed to a device buffer for each of the TPU cores taking part in training. The training thread (the main Python thread) takes the prefetched trajectories, computes gradients using the training TPU cores and applies the gradients on the models of all TPU cores (inference and training) synchronously. The ratio of inference and training cores can be adjusted for maximum throughput and utilization. The architecture scales to a TPU pod (2048 cores) by round-robin assigning actors to TPU host machines, and having separate inference threads for each TPU host. When actors wait for a response from the learner, they are idle so in order to fully utilize the machines, we run multiple environments on a single actor.
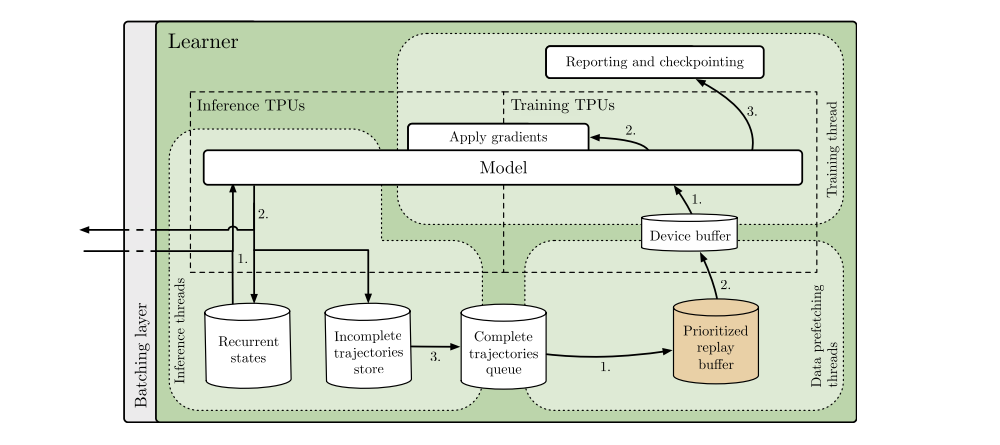
Detailed learner architecture in SEED (with an optional replay buffer)
To summarize, we solve the issues listed previously by:
-
Moving inference to the learner and thus eliminating any neural network related computations from the actors. Increasing the model size in this architecture will not increase the need for more actors (in fact the opposite is true).
-
Batching inference on the learner and having multiple environments on the actor. This fully utilize both the accelerators on the learner and CPUs on the actors. The number of TPU cores for inference and training is finely tuned to match the inference and training workloads. All factors help reducing the cost of experiments.
-
Everything involving the model stays on the learner and only observations and actions are sent between the actors and the learner. This reduces bandwidth requirements by as much as 99%.
-
Using streaming gRPC that has minimal latency and minimal overhead and integrating batching into the server module.
We provide the following two algorithms implemented in the SEED framework:
-
V-trace
We do not include any of the additions that have been proposed on top of IMPALA. The additions can also be applied to SEED and since they are more computational expensive, they would benefit from the SEED architecture.
-
Q-learning