Paper 22: Google Research Football: A Novel Reinforcement Learning Environment
Github: https://github.com/google-research/football.
Abstract
-
We introduce the Google Research Football Environment, a new RL environment where agents are trained to play football in an advanced, physics-based 3D simulator.
-
The environment is challenging, easy to use and customize, and it is available under a permissive open-source license. It provides support for multi-player and multi-agent experiments.
-
We propose three full-game scenarios of varying difficulty with the Football Benchmarks and report baseline results for three commonly used RL algorithms (IMPALA, PPO, and Ape-X DQN). We also provide a diverse set of simpler scenarios with the Football Academy and showcase several promising research directions.
1 Introduction
Games provide challenging environments where new algorithms and ideas can be quickly tested in a safe and reproducible manner.
While a variety of reinforcement learning environments exist, they often come with a few drawbacks for research.
This highlights the need for a RL environment that is not only challenging from a learning standpoint and customizable in terms of difficulty but also accessible for research both in terms of licensing and in terms of required computational resources. Moreover, such an environment should ideally provide the tools to a variety of current RL research topics such as the impact of stochasticity, self-play, multi-agent setups and model-based RL, while also requiring smart decisions, tactics, and strategies at multiple levels of abstraction.
In this paper, we propose the Google Research Football Environment, a novel open-source RL environment where agents learn to play one of the world’s most popular sports: football (a.k.a. soccer). Modeled after popular football video games, the Football Environment provides a physics-based 3D football simulation where agents have to control their players, learn how to pass in between them and how to overcome their opponent’s defense in order to score goals. This provides a challenging RL problem as football requires a natural balance between short-term control, learned concepts such as passing, and high level strategy. As our key contributions, we
-
provide the
Football Engine, a highly-optimized game engine that simulates the game of football, -
propose the
Football Benchmarks, a versatile set of benchmark tasks of varying difficulties that can be used to compare different algorithms, -
propose the
Football Academy, a set of progressively harder and diverse reinforcement learning scenarios, -
evaluate state-of-the-art algorithmson both the Football Benchmarks and the Football Academy, providing an extensive set of reference results for future comparison, -
provide a simple API to completely
customize and define new football RL scenarios, -
showcase several
promising research directionsin this environment, e.g. the multi-player and multi-agent settings.
2 Motivation and Other Related Work
There are a variety of RL environments that have accelerated research in recent years. However, existing environments exhibit a variety of drawbacks that we address with the Google Research Football Environment:
-
Easy to solve: Atari games in the Arcade Learning Environment; DeepMind Lab
-
Computationally expensive: StarCraft II Learning Environment
-
Lack of stochasticity: The real-world is not deterministic which motivates the need to develop algorithms that can cope with and learn from stochastic environments.
-
Lack of open-source license
-
Known model of the environment: Backgammon; Chess; Go
-
Single-player: some modern real-world applications involve a number of agents under either centralized or distributed control. The different agents can either collaborate or compete, creating additional challenges. A well-studied special case is an agent competing against another agent in a zero sum game. In this setting, the opponent can adapt its own strategy, and the agent has to be robust against a variety of opponents. Cooperative multi-agent learning also offers many opportunities and challenges, such as communication between agents, agent behavior specialization, or robustness to the failure of some of the agents. Multi-player environments with collaborative or competing agents can help foster research around those challenges.
-
Other football environments: RoboCup Soccer Simulator; DeepMind MuJoCo Multi-Agent Soccer Environment. In contrast to these environments, the Google Research Football Environment
focuses on high-level actions instead of low-level control of a physics simulation of robots. Furthermore, itprovides many useful settings for RL, e.g. the single-agent and multi-agent settings as well as single-player and multi-player player modes. It alsoprovides ways to adjust difficulty, both via a strength-adjustable opponent and via diverse and customizable scenarios in Football Academy, andprovides several specific features for RL research, e.g., OpenAI gym compatibility, different rewards, different representations, and the option to turn on and off stochasticity. -
Other related work: DeepMind Control Suite; AI Safety Gridworlds; Hanabi Learning Environment. Each of these environments are better suited for testing algorithmic ideas involving a limited but well-defined set of research areas.
3 Football Engine
The Football Environment is based on the Football Engine, an advanced football simulator built around a heavily customized version of the publicly available GameplayFootball simulator. The engine simulates a complete football game, and includes the most common football aspects, such as goals, fouls, corners, penalty kicks, or off-sides.

-
Supported Football Rules
-
Opponent AI Built-in Bots: The environment controls the opponent team by means of a rule-based bot, which was provided by the original GameplayFootball simulator. The difficulty level θ can be smoothly parameterized between 0 and 1, by speeding up or slowing down the bot reaction time and decision making. Some suggested difficulty levels correspond to: easy (θ = 0.05), medium (θ = 0.6), and hard (θ = 0.95). For
self-play, one can replace the opponent bot with any trained model. Moreover, by default, our non-active players are also controlled by another rule-based bot. In this case, the behavior is simple and corresponds to reasonable football actions and strategies, such as running towards the ball when we are not in possession, or move forward together with our active player. In particular, this type of behavior can be turned off for future research on cooperative multi-agents if desired. -
State & Observations
-
Actions
-
Rewards
-
Accessibility: Researchers can
directly inspect the gameby playing against each other or by dueling their agents. The game can be controlled by means of both keyboards and gamepads. Moreover, replays of several rendering qualities can be automatically stored while training, so that it is easy to inspect the policies agents are learning. -
Stochasticity: In order to investigate the impact of randomness, and to simplify the tasks when desired, the
environment can run in either stochastic or deterministic mode. The former, which is enabled by default, introduces several types of randomness: for instance, the same shot from the top of the box may lead to a different number of outcomes. In the latter, playing a fixed policy against a fixed opponent always results in the same sequence of actions and states. -
API & Sample Usage: Example code that runs a random agent on our environment:
import gfootball.env as football_env env = football_env.create_environment( env_name=’11_vs_11_stochastic’, render=True) env.reset() done = False while not done: action = env.action_space.sample() observation, reward, done, info = env.step(action) -
Technical Implementation & Performance: The Football Engine is written in highly optimized C++ code, allowing it to be run on commodity machines both with GPU and without GPU-based rendering enabled. This allows it to obtain a performance of approximately 140 million steps per day on a single hexacore machine.
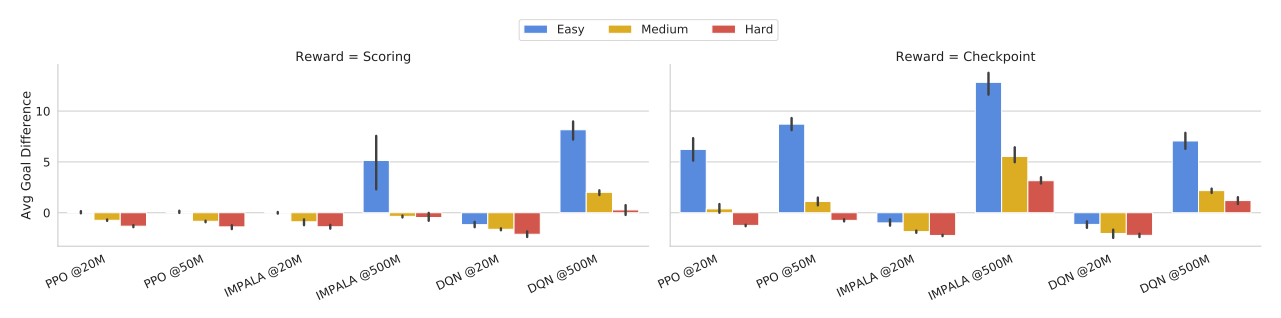
4 Football Benchmarks
The goal in the Football Benchmarks is to win a full game against the opponent bot provided by the engine. We provide three versions of the Football Benchmarks that only differ in the strength of the opponent AI as described in the last section: the easy, medium, and hard benchmarks. This allows researcher to test a wide range of research ideas under different computational constraints such as single machine setups or powerful distributed settings.
Experimental Setup
As a reference, we provide benchmark results for three state-of-the-art RL algorithms: PPO and IMPALA which are popular policy gradient methods, and Ape-X DQN, which is a modern DQN implementation. We run PPO in multiple processes on a single machine, while IMPALA and DQN are run on a distributed cluster with 500 and 150 actors respectively.
Results
5 Football Academy
To allow researchers to quickly iterate on new research ideas, we also provide the Football Academy: a diverse set of scenarios of varying difficulty.
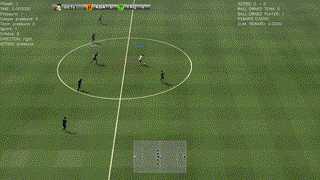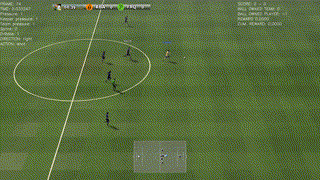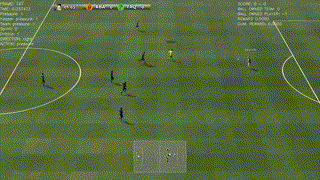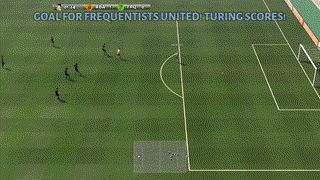
A successful policy that runs towards the goal (as required, since a number of opponents chase our player) and scores against the goal-keeper.
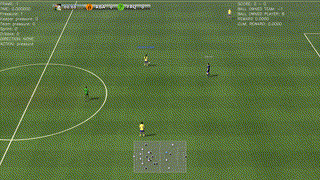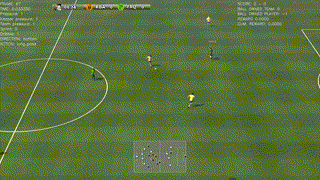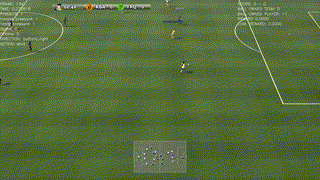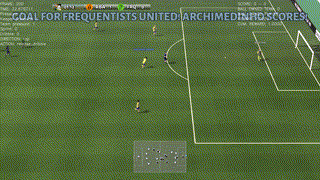
A beautiful way to drive and finish a counter-attack

A simple way to solve a 2-vs-1 play

The agent scores after a corner kick