Paper 25: Acme: A Research Framework for Distributed Reinforcement Learning
Github: https://github.com/deepmind/acme.
Abstract
-
We introduce Acme, a tool to simplify the development of novel RL algorithms that is specifically designed to enable simple agent implementations that can be run at various scales of execution.
-
Our aim is also to make the results of various RL algorithms developed in academia and industrial labs easier to reproduce and extend.
-
To this end we are releasing baseline implementations of various algorithms, created using our framework. In this work we introduce the major design decisions behind Acme and show how these are used to construct these baselines.
-
We also experiment with these agents at different scales of both complexity and computation—including distributed versions. Ultimately, we show that the design decisions behind Acme lead to agents that can be scaled both up and down and that, for the most part, greater levels of parallelization result in agents with equivalent performance, just faster.
1 Introduction
A characteristic of much of recent RL research has been an integrationist(整合主义)perspective on agent design, involving the combination of various algorithmic components. Agents may incorporate ideas such as intrinsic rewards and auxiliary(辅助的)tasks, ensembling, prioritized experience replay, distributional backups, specialized neural network architectures, policy improvement search methods, learning from demonstrations, variance reduction, hierarchy or meta-learning, to name a few examples. This has led to many state-of-the-art agents incorporating numerous heterogeneous(多样化的)components, contributing to their increased complexity and to growing concerns about the reproducibility of research.
Widespread use of increasingly large-scale distributed systems in RL agent training introduces numerous engineering and algorithmic challenges, and relies on significant amounts of infrastructure which can impede(阻止)the reproducibility of research. It also motivates agent designs that may represent dramatic departures from canonical abstractions laid out in the reinforcement learning literature. This often means that “scaling up” from a simple, single-process prototype of an algorithm to a full distributed system may require a reimplementation of the agent.
Acme is a software library and light-weight framework for expressing and training RL agents which attempts to address both the issues of complexity and scale within a unified framework, allowing for fast iteration of research ideas and scalable implementation of state-of-the-art agents. Acme does this by providing tools and components for constructing agents at various levels of abstraction, from the lowest (e.g. networks, losses, policies) through to workers (actors, learners, replay buffers), and finally entire agents complete with the experimental apparatus(装置)necessary for robust measurement and evaluation, such as training loops, logging, and checkpointing. The agents written in the framework are state-of-the-art implementations that promote the use of common tools and components, hopefully leading to common community benchmarks. Our modular design of Acme’s agents makes them easily scalable to large distributed systems, all while maintaining clear and straightforward abstractions and simultaneously supporting training in the non-distributed setting.
In what remains of this section, we give a brief overview of modern RL and discuss various software frameworks used to tackle such problems.
1.1 Modern Reinforcement Learning
Agent has to master two formidable challenges which align with the actor and learner processes. First, an agent must explore its environment effectively so as to obtain useful experiences. Second, it has to learn effectively from these experiences.
In online RL, both challenges are attacked simultaneously. As a result, vast numbers of interactions are often required to learn policies represented as DNNs. The need for data of this magnitude motivates the use of distributed agents as described above with many parallel actors. This is particularly important in simulated environments and games where massive amounts of experience can be gathered in a distributed manner and at rates substantially faster than real-time. At the other end of the spectrum lies offline RL—also known as batch RL—which focuses on the challenge of learning policies from a fixed dataset of experiences. This situation arises often in settings where online experimentation is impossible or impractical, e.g. industrial control and healthcare. Frequently, the goal of this setting is to learn a policy that outperforms those used to generate the dataset of past experiences. Of course there is also a great deal of work in between these two extremes, which is where most of the work on off-policy agents lies.
Acme is designed to greatly simplify the construction of agents in each of these settings. In Section 2 we introduce natural modules to the design of agents which correspond to the acting, dataset, and learning components. These allow us to tackle simple, classical on- and off-policy agents by combining all of the above in a synchronous setting. We can also separate the acting and learning components and replicate the actor processes to arrive at modern, distributed agents. And by removing acting completely and making use of a fixed dataset we can tackle the offline RL setting directly. Finally, in order to exemplify this split we will also detail in Section 3 a number of example learning components built using Acme and show how these can be combined to arrive at different algorithms.
1.2 Related work
-
OpenAI baselines and TF-Agents: written in TensorFlow 1.X, numerous algorithms in single-process format.
-
Dopamine: single-process agents in the DQN family, and various distributional variants including Rainbow, and Implicit Quantile Networks.
-
Fiber and Ray: generic tools for expressing distributed computations.
-
ReAgent: offline/batch RL from large datasets in production settings.
-
SEED RL: a highly scalable implementation of IMPALA that uses batched inference on accelerators to maximize compute efficiency and throughput.
-
TorchBeast: another IMPALA implementation written in Torch.
-
SURREAL: continuous control agents in a distributed training framework.
-
Arena: multi-agent reinforcement learning.
The design philosophy behind Acme is to strike a balance between simplicity and that of modularity and scale. This is often a difficult target to hit—often it is much easier to lean heavily into one and neglect the other. Instead, in Acme we have designed a framework and collection of agents that can be easily modified and experimented with at small scales, or expanded to high levels of data throughput at the other end of the spectrum. While we are focusing for the moment on releasing the single-process variants of these agents, the design philosophy behind the large-scale distributed versions remains the same.
2 Acme
Acme is a library and framework for building readable, efficient, research-oriented RL algorithms. At its core Acme is designed to enable simple descriptions of RL agents that can be run at many different scales of execution. While this usually culminates in running many separate (parallel) acting and learning processes in one large distributed system; we first describe Acme in a simpler, single-process setting, where acting and learning are perfectly synchronized. A key feature of Acme is that the agents can be run in both the single-process and highly distributed regimes using the exact same modules or building blocks with very limited differences. We achieve this by factoring the code into components that make sense at both ends of the scale. In what remains of this section we will discuss several of these components and how they interact.
2.1 Environments, actors, and environment loops
Acme assumes that the environment adheres to the dm_env.Environment interface. However, readers familiar with the dm_env.TimeStep interface, may notice that we’ve deliberately(故意地)omitted(遗漏)the environmental discount factor to simplify notation, as it often simply takes binary values to signal the end of an episode.
In Acme, the component that interacts most closely with the environment is the actor.
The interaction between an actor and its environment is mediated by an environment loop. Custom loops can easily be implemented but we provide a generic one that meets most of our needs and provides a simple entry point for interacting with any of the actors or agents implemented within Acme.
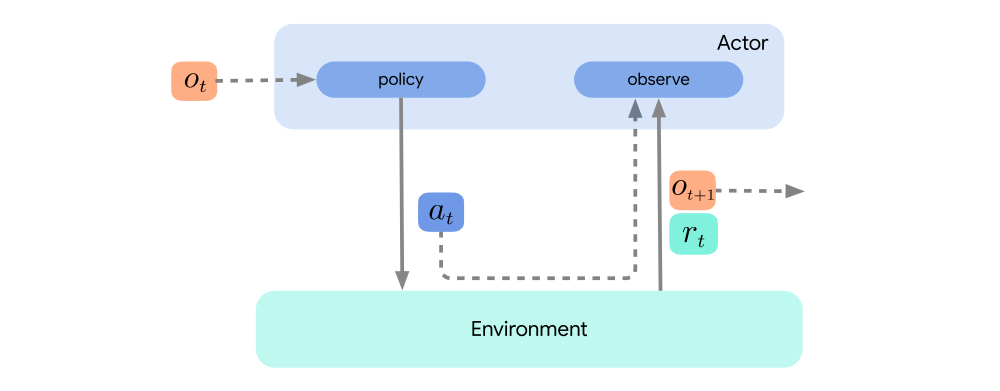
This following figure shows the pseudocode and includes a (slightly simplified) example of Acme’s implementation of this loop. one of the key design goals of Acme: wherever possible there should be a one-to-one mapping between typical RL pseudocode and its implementation.

2.2 Learners and Agents
We now introduce the learner component, which consumes training data in order to obtain a better policy. This component often contains the bulk of the code relevant to any specific RL algorithm and, in deep RL, takes the form of optimizing the weights of a neural network to minimize some algorithm-specific loss(es). More precise mathematical descriptions for a variety of algorithms will be detailed in Section 3. While it is possible to run a learner without further interaction with the environment, in RL we are often interested in concurrent learning and acting. Therefore we introduce a special type of actor that includes both an acting and a learning component; we refer to these as agents to distinguish them from their non-learning counterparts.
A generic actor’s update method simply pulls neural network weights from a variable source if it is provided one at initialization. Since a learner component is a valid variable source, the actor component may query a learner directly for its latest network weights. This will be particularly relevant when we discuss distributed agents in Section 2.4.
In the following figure we again show the environment loop, where we have expanded the interaction to show the internals of a learning agent we just described. While redundant, we sometimes use the term learning agent to emphasize that the agent contains a learner component. The illustration includes the actor and learner components and depicts how they interact. In particular, the actor pulls weights from the learner components in order to keep its action-selection up-to-date. Meanwhile, the learner pulls experiences observed by the actor through a dataset, which is yet another important component.
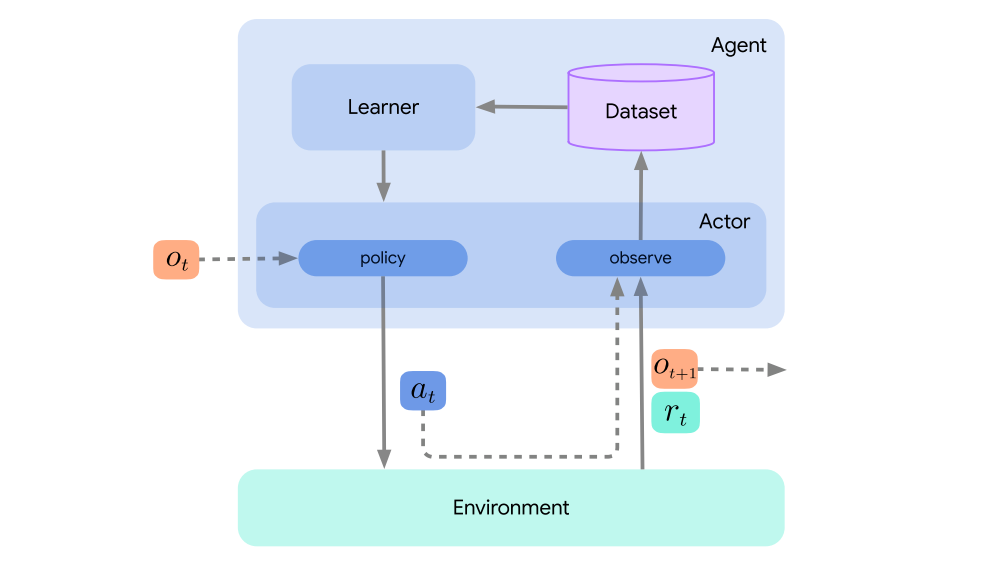
2.3 Datasets and Adders
While we have generally standardized on TensorFlow’s Dataset object to provide efficient buffering and iteration over data, this does not mandate(授权)the use of TensorFlow for the update step implemented by a learner. The dataset itself is backed by a low-level data storage system, called Reverb. Reverb can be roughly described as a storage system which enables efficient insertion and routing of items and a flexible sampling mechanism that allows: first-in-first-out, last-in-first-out, uniform, and weighted sampling schemes.
Acme also provides a simple common interface for insertion into the low-level storage system in the form of adders. Adders provide add methods which are analogous to the observe methods found on an actor—in fact most actors’ observations are forwarded directly onto an adder object. These objects exist in order to allow for different styles of preprocessing and aggregation of observational data that occurs before insertion into the dataset. For example a given agent implementation might rely on sampling transitions, n-step transitions, sequences (overlapping or not), or entire episodes—all of which have existing adder implementations in Acme.
Relying on different adder implementations to carry the workload of adding data once it is observed has also allowed us to design very general actor modules that support a wide variety of learning agents. While any agent is able to implement its own internal actor—or indeed bypass its actor component entirely and implement its own acting/observing methods directly as an agent is an actor in its own right—most agents are able to use one of these standard actors. Actors in Acme predominantly fall into one of two styles: feed-forward and recurrent. As their names suggest, these actors primarily differ in how they maintain state (or do not) between calls to the action-selection method, and the exact form of network used for these actors must be passed in at construction. Note that in Acme we have also taken pains to ensure that the communication between different components is agnostic(无关)to the underlying framework (e.g. TensorFlow) used. However, as the actors themselves must interact directly with this framework we also provide different implementations for both TensorFlow and JAX—and similar accommodations could be made for other frameworks.
Given these different modules we can easily construct novel algorithms by varying one or more components. However, easily composing modules in order to create novel agents is not the primary purpose of these components. Instead, in the next section we will describe how these modules can easily be pulled apart at the boundaries in order to enable distributed agents that can run at much larger scales.
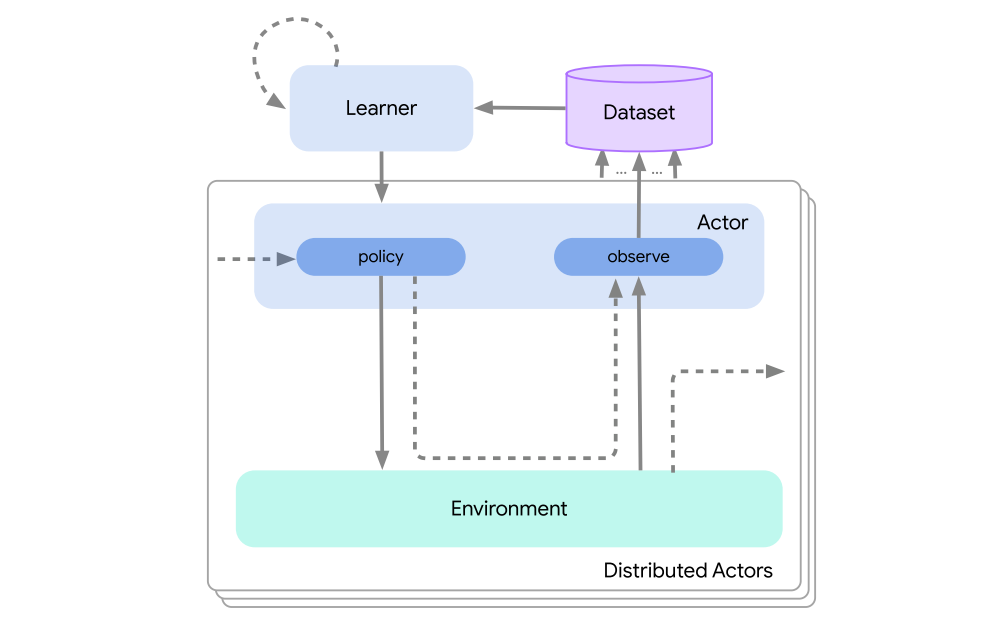
2.4 Distributed agents
A common use case is to generate data asynchronously from the learning process, often by interacting with multiple environments in parallel. In Acme we accomplish this by splitting the acting, learning, and storage components introduced earlier into different threads or processes. This has two benefits:
-
The first being that environment interactions can occur asynchronously with the learning process, i.e. we allow the learning process to proceed as quickly as possible regardless of the speed of data gathering.
-
The other benefit gained by structuring an agent in this way is that by making use of more actors in parallel we can accelerate the data generation process.
An example of a distributed agent is shown in the following figure.