Paper 36: Fiber: A Platform for Efficient Development and Distributed Training for Reinforcement Learning and Population-Based Methods
Abstract
-
RL and population-based methods in particular pose unique challenges for efficiency and flexibility to the underlying distributed computing frameworks.
-
These challenges include frequent interaction with simulations, the need for dynamic scaling, and the need for a user interface with low adoption cost and consistency across different backends.
-
We address these challenges while still retaining development efficiency and flexibility for both research and practical applications by introducing Fiber, a scalable distributed computing framework for RL and population-based methods.
-
Fiber aims to significantly expand the accessibility of large-scale parallel computation to users of otherwise complicated RL and population-based approaches without the need to for specialized computational expertise.
1 Introduction
RL and population-based methods pose unique challenges for reliability, efficiency, and flexibility that frameworks designed for supervised learning fall short of satisfying.
-
First, RL and population-based methods are typically applied in a setup that requires frequent interaction with simulators to evaluate policies and collect experiences.
-
Second, an ideal distributed computing framework should dynamically allocate resources for workloads whenever possible to ensure the maximum job throughput given a finite-size pool of computing resources.
-
Third, such a distributed computing framework should keep a unified user interface consistent across a wide variety of backends, enabling practitioners to effortlessly turn a prototype algorithm that runs on a laptop into a high-performance distributed application that runs efficiently on a multi-core workstation, over a cluster of machines, or even on a public cloud, all with relatively few additional lines of code.
Ray tries to provide a generalized solution for emerging AI applications including RL. It provides end-to-end distributed model training and serving. However, its design is influenced by Apache Spark and adopts some memory-intensive approaches (e.g. task dependency graphs, control and object stores) to support an internal task scheduler. This approach can be heavy-weight for algorithm development. Also, installing and deploying Ray on different backend platforms puts the burden of different customization on its users (Ray 2016).
In this paper we introduce Fiber, a scalable distributed computing framework for RL that aims to achieve both flexibility and efficiency while supporting both research and practical applications:
-
Fiber is built on a classic master-worker programming model, and introduces a task pool as a lightweight but effective strategy to handle the scheduling of tasks.
-
Fiber leverages cluster management software for job scheduling/tracking.
-
Fiber does not require pre-allocating resources and can dynamically scale up and down on the fly, ensuring maximal flexibility.
-
Fiber is designed with maximizing development efficiency in mind so the user can effortlessly migrate from multiprocessing on one machine to complete distributed training across multiple machines. The architecture of Fiber and experiments demonstrating its advantages are presented in this paper.
2 Background
This section briefly reviews RL and population-based methods, the targeted applications of Fiber, followed by a review of core concepts and components behind Fiber, e.g. multiprocessing, containers, and cluster management systems.
-
Population-based methodsare an additional class of search algorithms that can solve RL problems. They maintain a population of candidate solutions wherein encouraging behavioral diversity is a central drive. They have produced SOTA results in robotics and some hard-exploration RL problems. RL and population-based methods pose unique challenges to distributed training that Fiber aims to address. -
Multiprocessingis a Python standard library for parallel computing. It makes it easy for users to create new processes and create a pool of workers towards which tasks can be distributed. It is designed to leverage the computational power of modern multi-core CPUs on a single machine. Fiber follows the same interface as multiprocessing while extending many multiprocessing components to make them work in a distributed environment (i.e. across many computers in a computer cluster). -
Cluster management systemsmanage computer clusters and many machines simultaneously. They are the “operating system” layer on top of computer clusters and allow other applications to run on top of them. Examples include Apache Mesos, Kubernetes, Uber Peloton and Slurm. -
Containersare a method of virtualization that package an application’s code and dependencies into a single object. The aim is to allow application to run reliably and consistently from one environment to another environment. Containers are often used together with cluster management systems.
3 Approach: Fiber
Fiber provides users the ability to write applications for a large computer cluster with a standard and familiar library interface. This section covers Fiber’s design and applications.
3.1 Architecture
Fiber bridges the classical multiprocessing API with a flexible selection of backends that can run on different cluster management systems. To achieve this integration, Fiber is split into 3 different layers.
-
The API layer provides basic building blocks for Fiber like processes, queues, pools and managers. They have the same semantics as in multiprocessing, but are extended to work in distributed environments.
-
The backend layer handles tasks like creating or terminating jobs on different cluster managers. When a new backend is added, all the other Fiber components (queues, pools, etc.) do not need to be changed.
-
Finally, the cluster layer consists of different cluster managers. Although they are not a part of Fiber itself, they help Fiber to manage resources and keep track of different jobs, thereby reducing the number of items that Fiber needs to track.
This overall architecture is summarized in figure 1.
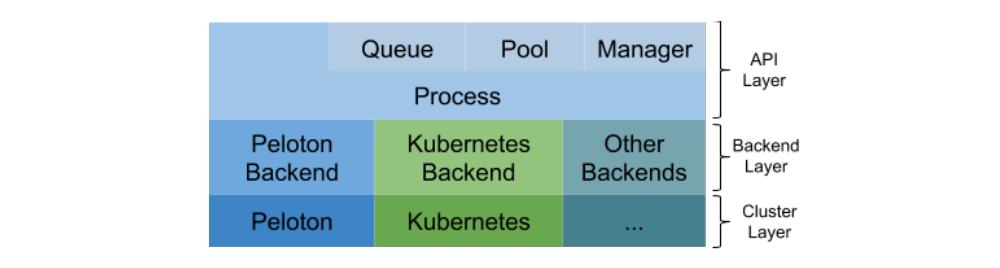
Figure 1: Fiber architecture.
3.2 Fundamentals
Fiber introduces a new concept called job-backed processes. It is similar to the process in Python’s multiprocessing library, but more flexible: while a process in multiprocessing only runs on a local machine, a Fiber process can run remotely on a different machine or locally on the same machine. When starting a new Fiber process, Fiber creates a new job with the proper Fiber backend on the current computer cluster. Fiber uses containers to encapsulate the running environment of current processes, including all the required files, input data, and other dependent program packages, etc., to ensure everything is self-contained. All the child processes are started with the same container image as the parent process to guarantee a consistent running environment. Because each process is a cluster job, its life cycle is the same as any job on the cluster. To make it easy for users, Fiber is designed to directly interact with computer cluster managers. Because of this, Fiber doesn’t need to be set up on multiple machines or bootstrapped by any other mechanisms, unlike Spark or IPyParallel. It only needs to be installed on a single machine as a normal Python pip package.
3.3 Components
Fiber implements most multiprocessing APIs on top of Fiber processes including pipes, queues, pools and managers. These components are critical to implement RL algorithms and population-based methods.
import random
import fiber
def worker(p):
return random.random()**2 + random.random()**2 < 1
def main():
NUM_SAMPLES = int(1e7)
# fiber.Pool manages a list of distributed workers
pool = fiber.Pool(processes=4)
count = sum(pool.map(worker, range(0, NUM_SAMPLES)))
print("Pi is roughly {}".format(4.0 * count / NUM_SAMPLES))
if __name__ == "__main__":
main()
Supported multiprocessing components. Queues and pipes in Fiber behave the same as in multiprocessing. The difference is that queues and pipes are now shared by multiple processes running on different machines. Two processes can read from and write to the same pipe. Furthermore, queues can be shared between many processes on different machines and each process can send to or receive from the same queue at the same time. Pools are also supported by Fiber. They allow the user to manage a pool of worker processes. Fiber extend pools with job-backed processes so that it can manage thousands of (remote) workers per pool. Users can also create multiple pools at the same time. Managers and proxy objects enable multiprocessing to support shared storage, which is critical to distributed systems. Usually, this function is handled by external storage like Cassandra, Redis, etc. Fiber instead provides built-in in-memory storage for applications to use. The interface is the same as multiprocessing’s Manager type. In this way, Fiber provides a shared storage that is convenient to use and high performance.
Unsupported multiprocessing components. Shared memory is used heavily by frameworks like PyTorch and Ray. In general, it can improve performance of inter-process communications on the same machine. However, it is not available when communicating over computer network, which is common for distributed systems. Thus Fiber provides managers and proxy objects as the primary means to share data instead. Locks can be very import for coordinating between different processes and preventing race conditions. However, in a distributed environment, it may cause wasting large amount of computation resources. Therefore, we excluded locks from the supported APIs as it’s not needed by most RL and population-based methods.
3.4 Applications
RL and population-based methods are two major applications for Fiber. These algorithms generally require frequent interactions between policies (usually represented by a neural network), and environments (usually represented by a simulator like ALE, OpenAI Gym, and Mujoco. The communication pattern for distributed RL and population-based methods usually involves sending different types of data between machines: actions, neural network parameters, gradients, per-step/episode observations and rewards, etc. Actions can be either discrete (represented by an integer) or continuous (represented by a float number). The number of actions that needs to be transmitted are usually less than a thousand. The size of observations and neural network parameters can be larger than actions. Depending on the neural network used, the size of parameters (and gradients) can range from bytes to megabytes.
Fiber implements pipes and pools to transmits these data. Under the hood, pools are normal Unix sockets, providing near line-speed communication for the applications using Fiber. Modern computer networking usually has bandwidth as high as hundreds of gigabits per second. Transmitting smaller amount of data over a network is usually fast. Fiber can run each simulator in a single process and communicate actions, observations, rewards, parameters or gradients via pipes between different processes. If the size of parameters or gradients is too large, Fiber can be used together with Horovod, which leverages GPU to GPU communication for faster communication. Additionally, the inter-process communication latency does not increase much if there are many different processes sending data to one process because data transfer can happen in parallel. This fact makes Fiber’s pools suitable for creating the foundation of many RL and population-based learning algorithms because simulators can run in each pool worker process and the results can be transmitted back in parallel.
def evaluate(theta):
# do rollout and return the reward
return reward
def train():
N = 1000
workers = 10
# fiber.Pool manages a list of distributed workers
pool = fiber.Pool(workers)
theta = init()
for i in range(n):
noises = [sample_noise() for i in range(N)]
thetas = [theta + sigma * noise for noise in noises]
rewards = pool.map(evaluate, thetas)
s = sum([rewards[i] * noises[i] for i in range(N)])
theta = alpha/(workers * sigma) * s
The distinction between pool- and pipe-based communication is that pools usually ignore task order while pipes keep order. For pools, each task (neural network evaluation, etc.) can be mapped to any of the worker processes. This is suitable for algorithms like ES or POET, where each task is stateless. Each evaluation can run on any of the pool worker processes and only the (per episode) end results need to be collected back in parallel. An example of ES algorithm implemented with Fiber is listed in code example above. On the other hand, pipes can maintain the order of each task. Each simulator is mapped to a fixed process so that worker processes can maintain their internal state after each step. At each step, each worker process only needs to accept actions that are for that specific worker and send the results (instantaneous rewards, state transitions, etc.) back. This makes it suitable for RL algorithms like A3C, PPO, etc. An example of RL implemented in Fiber is listed in the following code example.
# fiber.BaseManager is a manager that runs remotely
class RemoteEnvManager(fiber.BaseManager):
pass
class Env(gym.env):
# gym env
pass
RemoteEnvManager.register(’Env’, Env)
def build_model():
# create a new policy model
return model
def update_model(model, observations):
# update model with observed data
return new_model
def train():
model = build_model()
manager = RemoteEnvManager()
num_envs = 10
envs = [manager.env() for i in range(num_envs)]
obs = [envs[i].reset() for i in range(num_envs)]
for i in range(1000):
actions = model(obs)
obs = [env.step() for action in actions]
model = update_model(model, obs)
3.5 Scalability
There are two key considerations on scalability:
-
how many resources a framework can manage
-
how many resources an algorithm can use.
Because Fiber relies on the cluster scheduler to manage the resources including CPU cores, memory and GPUs, there is little role for Fiber in managing the resources except in tracking started processes and properly terminating them when computation is completed. Fiber schedules each task at most once. When batching is enabled, multiple tasks can be scheduled at the same time to improve efficiency. It is also possible to run Fiber across multiple clusters, but the network communication cost could make Fiber less efficient. Because Fiber does not require pre-allocating resources, it can scale up and down with the algorithm it runs. Compared to static allocation, Fiber can return unused resources back to the cluster when they are not needed. Furthermore, when it needs more resources, it can ask the cluster manager for more resources. This approach makes it suitable for algorithms that runs heterogeneous tasks in different stages.
3.6 Error Handling
Fiber implements pool-based error handling (Figure 2). When a new pool is created, an associated task queue, result queue and pending(待定)table are also created. Newly created tasks are then added to the task queue, which is shared between the master process and worker processes. Each of the workers fetches a single task from the task queue, and then runs task functions within that task. Each time a task is removed from the task queue, an entry in the pending table is added. Once the worker finishes that task, it puts its results in the result queue. The entry associated with that task is then removed from the pending table.
If a pool worker process fails in the middle of processing, that failure is detected by the parent pool that serves as the process manager of all the worker processes. Then the parent pool puts the pending task from the pending table back into task queue if the previously failed process has a pending task. Next, it starts a new worker process to replace the previously failed process and binds the newly created worker process to the task queue and the result queue.
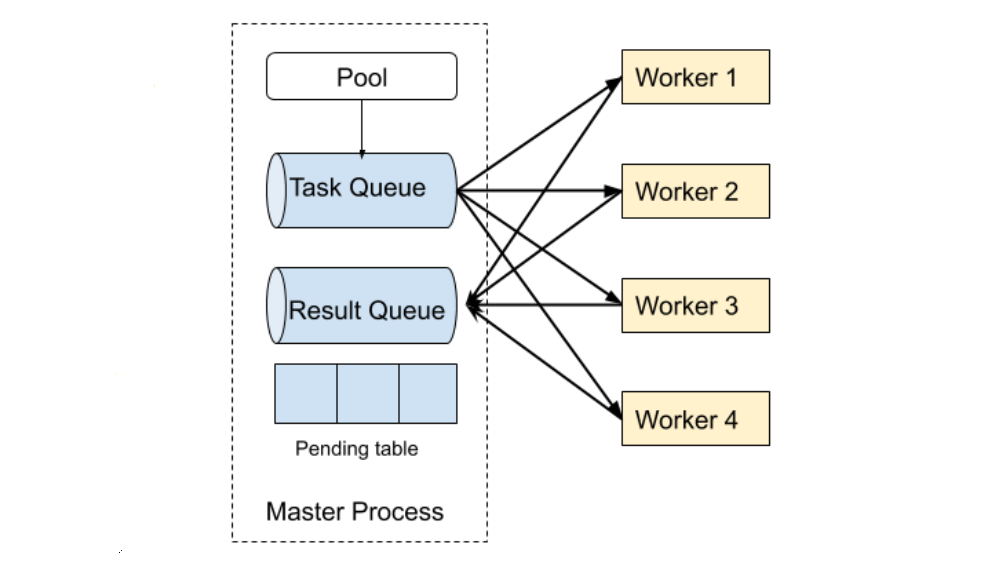
Figure 2: Task execution failure handling.