Paper 42: A Solution to China Competitive Poker Using Deep Learning
Abstract
-
Compared to Go, China Competitive Poker, also known as Dou dizhu(斗地主), is a type of imperfect information game, including hidden information, randomness, multi-agent cooperation and competition.
-
We introduce an approach to play China Competitive Poker using CNN to predict actions. This network is trained by supervised learning from human game records.
1 Introduction
Compared to Go, China Competitive Poker (CCP) is a kind of imperfect information game, starts from a random state. A player gets different cards each game, does not know the cards distribution of the other two players. Like bridge, Peasants must coordinate with each other, otherwise they could hardly beat the Landlord. CCP is a good problem for game AI. We choose CNN to solve the problem in CCP due to the following reasons:
-
First, CNN has achieved superhuman performance in perfect information games.
-
Second, there is semi-translational invariance in CCP, e.g. there are two sets of cards in the same category but with different ranks (like “34567” and “45678”, see more information in section 3), if we add each card’s rank, “34567” become “45678”, this is translational invariance. The player can play out “45678” after another one played out “34567”, but it is illegal if we swap the order, this is the reason for “semi”.
There is no AI about CCP using DNN so far. It is still to be proved that the network can output a proper action with an imperfect information input in CCP. The same factor between CCP and Go is blurred when making a decision. It is very hard to evaluate the value of alternative actions in Go, also CCP. Two problems:
-
As there are teammates in CCP, one problem is to teach the network to cooperate, e.g. how to help teammate become the first one to play out all cards, while his cards is not good enough.
-
Another problem we are interested in is inference, whether the network is able to analyze like human experts’ logic.
The DeepRocket, which is developed by us, gets the SOTA performance in CCP. We prove that the network can learn cooperate and inference in imperfect information game.
3 Notations
The Specified Player; Down Player; Up Player; Landlord(地主); Down Peasant(农民); Up Peasant; Public Cards; Round; Category; Main Group and Kicker Card; Set or Group; Active Mode; Passive Mode; Duplicate Mode
4 DeepRocket Framework
The system consists of three parts:
-
the Bid Module. When game starts, the Bid Module is called in order to make DeepRocket output score, if necessary.
-
the Policy Network. The Policy Network is called before DeepRocket will do action, the output may contain Kicker Card type (solo or pair) in some labels.
-
the Kicker Network. If there is a Kicker card need to be predicted, then the Kicker Network is called, as shown in Figure 1 and Figure 2.
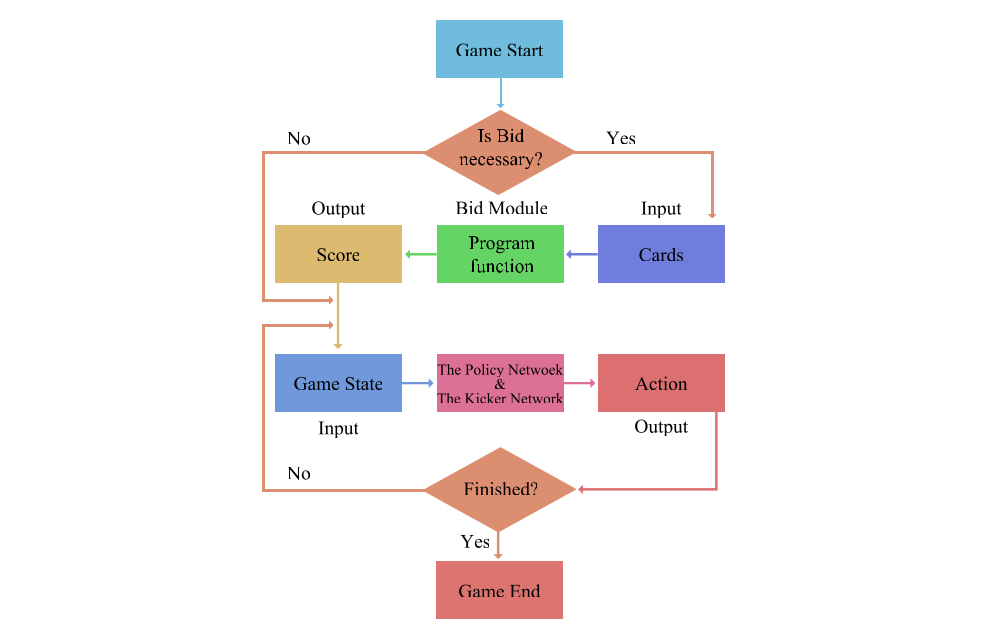
Figure 1: DeepRocket game flow
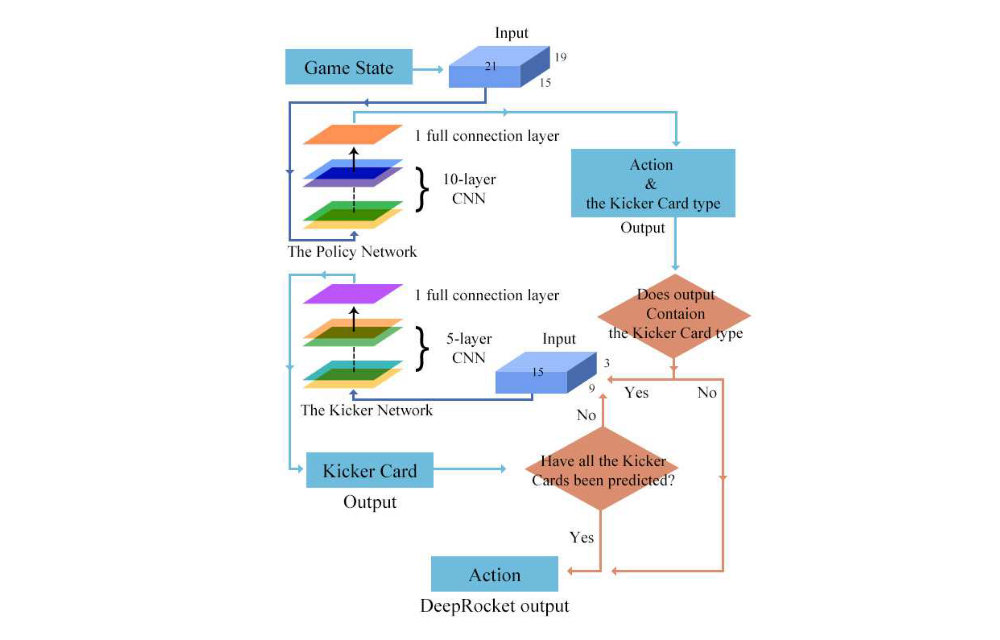
Figure 2: The Policy Network and The Kicker Network work flow
4.1 The Bid Module
First of all, the game need to make sure who is Landlord by bid after players get cards, so we design the module for bid. The key factors of bid is cards. The Bid module is based on logic code. Like human experts, the output of module depends on control cards (like “A”, “2”, and “jokers”) and tidiness(整齐度)(that means less sets combined by cards). The module have been used on many online platform in business in China, and it is proved that works well. Bid is not used in Duplicate Mode, also in test, we do not introduce more details and focus on other components of DeepRocket.
4.2 The Policy Network
Like AlphaGo, we trained the Policy Network to predict human expert actions using supervised learning. The Policy Network consists of 10-layer CNN and 1 full connection layer, use Relu as activation function. A final softmax layer outputs probability distribution over all legal action a. The input represents current game state. The Policy Network is trained on randomly sampled state-action pairs (s, a), using stochastic gradient ascent to maximize the likelihood of the human expert action. We use 8 million game records for training the Policy Network. One record represents a complete game, and can be divided into many state-action pairs, from several rounds to more than twenty rounds, depending on length of the records. Here is a example, see Appendix A for more details about the game record.

Figure 3: Example Game Record
If we want to learn Down Peasant, the record should be divided into the state-action pairs.
The input to the Policy Network is a 15×19×21 3-dimensional binary tensor (we name the corresponding dimension X, Y, and Z respectively). Each dimension along X-axis represents the ranks of cards, from 3 to big joker. Y-axis represents the number of each rank (from 1 to 4), and features in CCP, such as solo, pair, trio, etc. Z-axis represents the sequential information of each rounds, this design learned from AlphaGo, make the variable length to fixed length in game. Finally, the most recent 6 rounds are chosen. Si,j,k standards the binary feature for current state of the game. Details are shown in figure 4.

Figure 4: The meaning of Z-axis
512 filters are the most suitable after models are tested. 10-layers CNN achieved the best performance after repeated testing, different strides are used in each layer.
The Policy Network outputs 309 action probabilities after we add the Kicker Network to DeepRocket, See figure 5. It is noteworthy that the maximum number of cards is 20, it restricts the longest length of category.
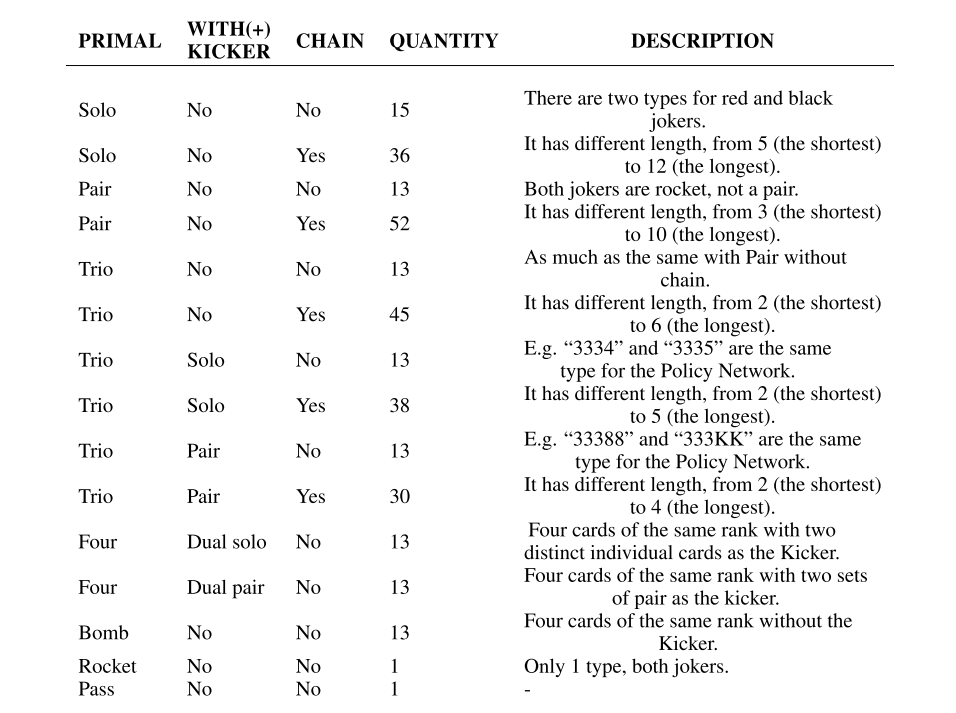
Figure 5: The output’s composition PRIMAL
4.3 The Kicker Network
A combination of the Bid Module and the Policy Network suffices to play a game in principle. However, there is a problem dealing with Kicker Cards. If there are n choice for the Main Group and m for the Kicker Cards, then there are n×m available actions in total. In some other case, if the player has trio with chain (e.g. “333444” is a trio with chain), the length is i (the length of ”333444” is 2), and j for available Kicker Cards, then there are Ci j choice in total. For example, “333444555666789J” is a legal action, but the sample is hardly found in even 8 million game records. Furthermore, Main Group with different Kicker Cards is labeled as different actions, and thereby a combinatorial number of different actions to be predicted by the Policy Network.
In order to address this problem, we add an extra network for predicting the Kicker Card. The Policy Network predict the Main Group and Kicker Cards type, like solo or pair, then the Kicker Network predict the kicker cards. This make the Policy Network only output 309 probabilities rather than thousands. For example, “333444555666789J” and “333444555666789Q” are the same output in the Policy Network (outputs “333444555666” and solo kicker cards) while “789J” or “789Q” is predicted by the Kicker Network.
The input to the Kicker Network, which include the remaining cards and the output of the Policy Network is a 15×9×3 3-dimensional binary tensor. Each dimension along X-axis represents the cards, is the same as the Policy Network. Figure 6 shows the details about Y-axis and Z-axis. The Kicker Network has 28 outputs, include 15 kinds of solo and 13 kinds of pair.

Figure 6: The kicker network’s input channel CHANNEL/PLANE