Paper 50: Soft Q-Network (SQN)
Abstract
Instead of adding more and more small fixes on DQN model, we redesign the problem setting under a popular entropy regularization framework which leads to better performance and theoretical guarantee. Finally, we purposed SQN, a new off-policy algorithm with better performance and stability.
1 Introduction
Most of the current method (extensions of DQN) is easily suffer from the local optimal position, they find a solution looks good in a shorter view, but often sacrifice the performance in the long run, for example, maybe the agent learns to stay still to avoid death, it’s not something we want. Second, the model-free method has a bad name for its low sample efficiency, even some simple tasks need millions of interval with the environment when it comes to complex decision-making problem, which is inaccessible for most domain except in some really fast simulator.
Many methods are often extremely brittle with respect to their hyperparameters and they often have so much hyperparameters that need to be tuned. It means we need carefully tuning the parameters, most important, they often suck to local optimal. In many cases they fail to find a reward signal, even when the reward signal is relatively dense, they still fail to find the optimal solution, some researchers design such a complex reward function for each environment they want to solve.
In this paper, we propose a different approach to deal with complex tasks with DRL and investigate an entropy regularization approach to learning a good policy under the SQN framework. Extensive experiments on Atari tasks demonstrate the effectiveness and advantages of the proposed approach, which performs the best among a set of previous SOTA methods.
2 Background
2.1 MDP
2.2 Soft Actor Critic
3 Method
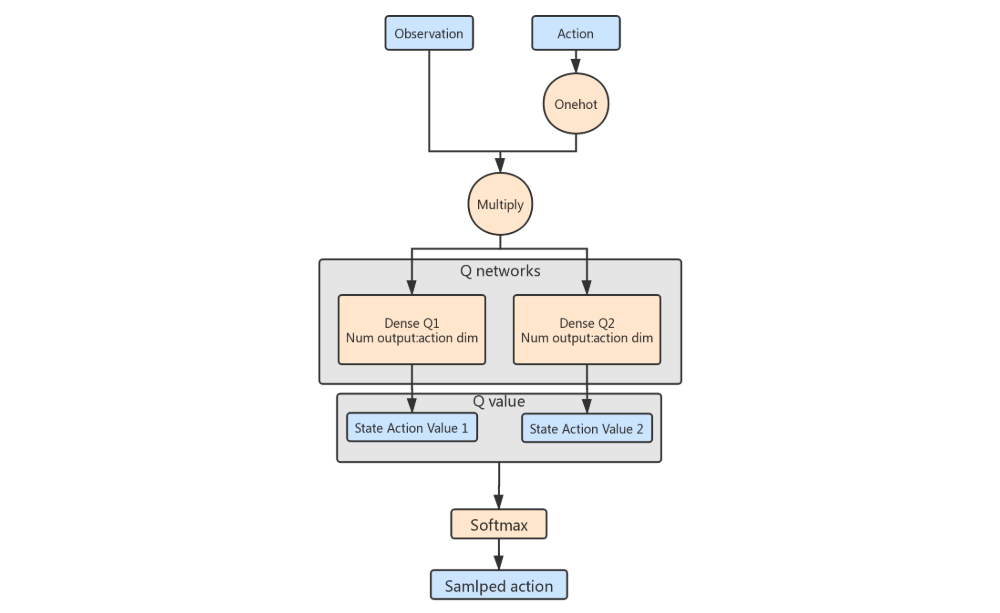
In particular, SAC makes use of two soft Q-functions to mitigate positive bias in the policy improvement step that is known to degrade the performance of value-based methods, Function approximators are used for both the soft Q-function and the policy. Instead of running evaluation and improvement to convergence, we alternate between optimizing both networks with SGD. We will consider two parameterized soft Q-function Qφ1, Qφ2 and a tractable policy πθ. The parameters of these networks are φ and θ.
-
Learning Functions
The Q-functions are learned by MSBE minimization, using a target value network to form the Bellman backups. They both use the same target, like in TD3, and have loss functions:
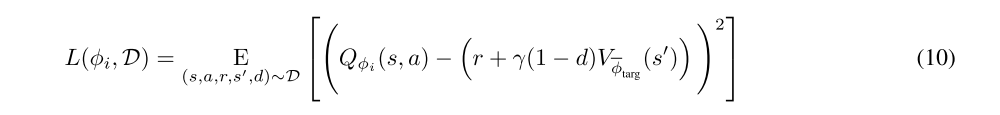
As for target value network, we can obtain it by averaging the value network parameters over the course of training. It’s not hard to rewrite the connection equation between value function and Q-function as follows:
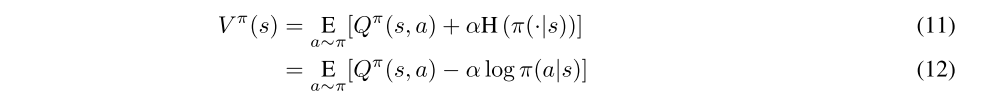
The value function is implicitly parameterized through the soft Q-function parameters via Equation 12. We use clipped double-Q like TD3 and SAC for express the TD target, and takes the minimum Q-value between the two approximators, So the loss for Q-function parameters are:
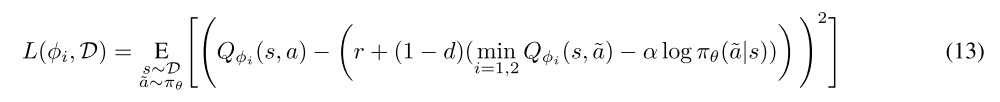
The update makes use of a target soft Q-function, that is obtained as an exponentially moving average(指数加权平均)of the soft Q-function weights, which has been shown to stabilize training. Importantly, we do not use actions from the replay buffer here: these actions are sampled fresh from the current version of the policy.
-
Learning the Policy
The policy should, in each state, act to maximize the expected future return plus expected future entropy. That is, it should maximize Vπ(s), which we expand out (as before) into
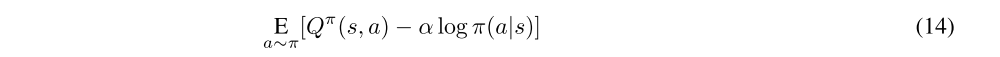
The target density is the Q-function, which is represented by a neural network and can be differentiated, and it is thus convenient to apply the reparameterization trick instead, resulting in a lower variance estimate, in which a sample from πθ(·|s) is drawn by computing a deterministic function of the state, policy parameters, and independent noise. following the authors of the SAC paper, we use a squashed Gaussian policy, which means that samples are obtained according to
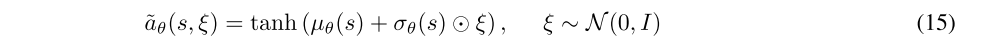
The reparameterization trick allows us to rewrite the expectation over actions (which contains a pain point: the distribution depends on the policy parameters) into an expectation over noise (which removes the pain point: the distribution now has no dependence on parameters):
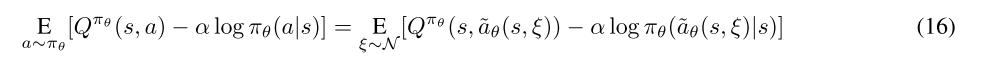
To get the policy loss, the final step is that we need to substitute Qπθ with one of our function approximators. The same as in TD3, we use Qφ1. The policy is thus optimized according to
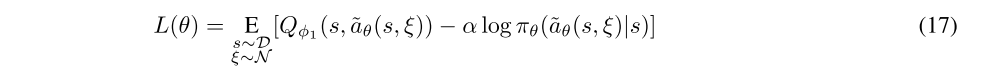
-
Learning α
As it proposed in SAC, for the purpose of improving performance, we learning the temporal parameter α by minimizing the dual objective as well:
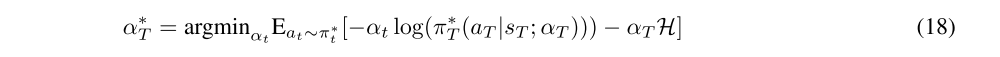
Prior give us tools to achieve this, approximating dual gradient descent is a way to achieve that. Because we use a function approximator and it is impractical to optimizing with respect to the primal variables fully, we compute gradients for α with the following objective:
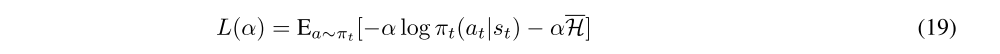
Inspired by SAC we derived our SQN method, SAC is aimed for discrete space so the policy network is necessary however here DQN gives great example of how to sample an action directly from Q function, combine this two idea means sample an action with entropy bonus, it comes to:
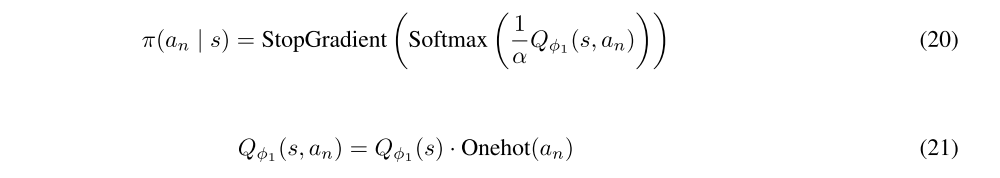
The final algorithm is listed in Algorithm 1.

It clearly shows that policy parameter update step won’t exist at all. As for value function update, it is same to SAC which described in section 3. The method alternates between collecting experience from the environment with the current policy and updating the function approximators using the stochastic gradients from batches sampled from a replay pool. Using off-policy data from a replay pool is feasible because both value estimators and the policy can be trained entirely on off-policy data. The algorithm is agnostic to the parameterization of the policy, as long as it can be evaluated for any arbitrary state-action tuple.