Paper 52: Sample Factory: Egocentric 3D Control from Pixels at 100000 FPS with Asynchronous Reinforcement Learning
Sample Factory 把强化学习单机架构的效率提高到了极致, 可以大大提高学习和研究的效率。 目前的 Sample Factory 只实现了 APPO, 其实 off-policy 的算法使用 Sample Factory 更有优势, 因为原本 on-policy 算法 off-policy 化带来的问题会有所减弱。
Github: https://github.com/alex-petrenko/sample-factory.
Abstract
-
Increasing the scale of RL experiments has allowed researchers to achieve unprecedented results in both training sophisticated agents for video games, and in sim-to-real transfer for robotics. Typically such experiments rely on large distributed systems and require expensive hardware setups, limiting wider access to this exciting area of research.
-
In this work we aim to solve this problem by optimizing the efficiency and resource utilization of RL algorithms instead of relying on distributed computation. We present the “Sample Factory”, a high-throughput training system optimized for a single-machine setting.
-
Our architecture combines a highly efficient, asynchronous, GPU-based sampler with off-policy correction techniques, allowing us to achieve throughput higher than 105 environment frames/second on non-trivial control problems in 3D without sacrificing sample efficiency.
-
We extend Sample Factory to support self-play and population-based training and apply these techniques to train highly capable agents for a multiplayer first-person shooter game.
1 Introduction
Despite major improvements in the sample efficiency of modern learning methods, most of them remain notoriously(众所周知的)data-hungry. For the most part, the level of results in recent years has risen due to the increased scale of experiments, rather than the efficiency of learning. Billion-scale experiments with complex environments are now relatively commonplace, and the most advanced efforts consume trillions of environment transitions in a single training session.
To minimize the turnaround time of these large-scale experiments, the common approach is to use distributed supercomputing systems consisting of hundreds of individual machines. Here, we show that by optimizing the architecture and improving the resource utilization of RL algorithms, we can train agents on billions of environment transitions even on a single compute node. We present the “Sample Factory”, a high-throughput training system optimized for a single-machine scenario. Sample Factory, built around an Asynchronous Proximal Policy Optimization (APPO) algorithm, is a RL architecture that allows us to aggressively parallelize the experience collection and achieve throughput as high as 130000 FPS (environment frames per second) on a single multi-core compute node with only one GPU. We describe theoretical and practical optimizations that allow us to achieve extreme frame rates on widely available commodity hardware.
We evaluate our algorithm on a set of challenging 3D environments and demonstrate how to leverage vast amounts of simulated experience to train agents that reach high levels of skill. We then extend Sample Factory to support self-play and population-based training and apply these techniques to train highly capable agents for a full multiplayer game of Doom.
3 Sample Factory
Sample Factory is an architecture for high-throughput RL on a single machine. When designing the system we focused on making all key computations fully asynchronous, as well as minimizing the latency and the cost of communication between components, taking full advantage of fast local messaging.
A typical RL scenario involves three major computational workloads: environment simulation, model inference, and backpropagation. Our key motivation was to build a system in which the slowest of three workloads never has to wait for any other processes to provide the data necessary to perform the next computation, since the overall throughput of the algorithm is ultimately defined by the workload with the lowest throughput. In order to minimize the amount of time processes spend waiting, we need to guarantee that the new portion of the input is always available, even before the next step of computation is about to start. The system in which the most compute-intensive workload never idles can reach the highest resource utilization, thereby approaching optimal performance.
3.1 High-level design
The desire to minimize the idle time for all key computations motivates the high-level design of the system. As illustrated in the following figure, N parallel rollout workers simulate k environments each, collecting observations. These observations are processed by M policy workers, which generate actions and new hidden states via an accelerated forward pass on the GPU. Complete trajectories are sent from rollout workers to the learner. After the learner completes the backpropagation step, the model parameters are updated in shared CUDA memory and immediately fetched by the policy workers.
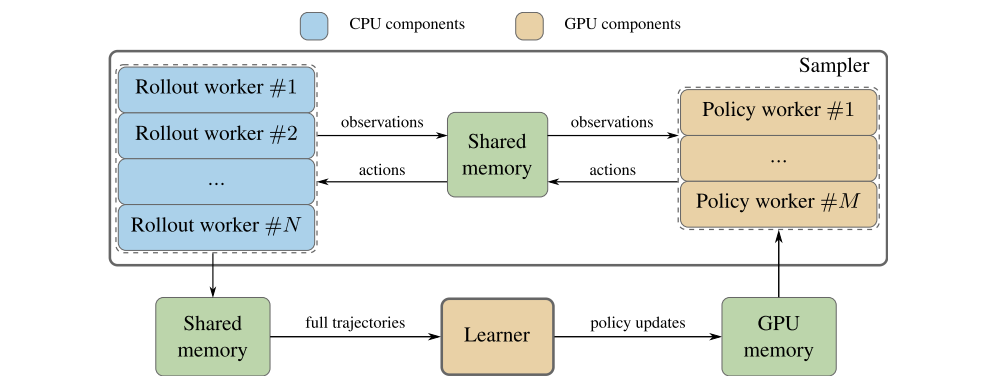
High-level architecture of Sample Factory
We associate each computational workload with one of three dedicated types of components. These components communicate with each other using a fast protocol based on FIFO queues and shared memory. The queueing mechanism provides the basis for continuous and asynchronous execution, where the next computation step can be started immediately as long as there is something in the queue to process. The decision to assign each workload to a dedicated component type also allows us to parallelize them independently, thereby achieving optimized resource balance. This is different from prior work, where a single system component, such as an actor, typically has multiple responsibilities. The three types of components involved are rollout workers, policy workers, and learners.
-
Rollout workers
Rollout workers are solely responsible for environment simulation. Each rollout worker hosts k ≥ 1 environment instances and sequentially interacts with these environments, collecting observations xt and rewards rt. Note that the rollout workers do not have their own copy of the policy, which makes them very lightweight, allowing us to massively parallelize the experience collection on modern multi-core CPUs.
The observations xt and the hidden states of the agent ht are then sent to the policy worker, which collects batches of xt, ht from multiple rollout workers and calls the policy π, parameterized by the neural network θπ to compute the action distributions µ(at|xt, ht), and the updated hidden states ht+1. The actions at are then sampled from the distributions µ, and along with ht+1 are communicated back to the corresponding rollout worker. This rollout worker uses the actions at to advance the simulation and collect the next set of observations xt+1 and rewards rt+1.
Rollout workers save every environment transition to a trajectory buffer in shared memory. Once T environment steps are simulated, the trajectory of observations, hidden states, actions, and rewards τ = x1, h1, a1, r1, …, xT, hT, aT, rT becomes available to the learner. The learner continuously processes batches of trajectories and updates the parameters of the actor θπ and the critic θV. These parameter updates are sent to the policy worker as soon as they are available, which reduces the amount of experience collected by the previous version of the model, minimizing the average policy lag. This completes one training iteration.
-
Parallelism
As mentioned previously, the rollout workers do not own a copy of the policy and therefore are essentially thin wrappers around the environment instances. This allows them to be massively parallelized. Additionally, Sample Factory also parallelizes policy workers. This can be achieved because all of the current trajectory data (xt, ht, at, …) is stored in shared tensors that are accessible by all processes. This allows the policy workers themselves to be stateless, and therefore consecutive trajectory steps from a single environment can be easily processed by any of them. In practical scenarios, 2 to 4 policy worker instances easily saturate the rollout workers with actions, and together with a special sampler design (section 3.2) allow us to eliminate this potential bottleneck.
The learner is the only component of which we run a single copy, at least as long as single-policy training is concerned (multi-policy training is discussed in section 3.5). We can, however, utilize multiple accelerators on the learner through data-parallel training and Hogwild-style parameter updates. Together with large batch sizes typically required for stable training in complex environments, this gives the learner sufficient throughput to match the experience collection rate, unless the computational graph is highly non-trivial.
3.2 Sampling
Rollout workers and policy workers together form the sampler. The sampling subsystem most critically affects the throughput of the RL algorithm, since it is often the bottleneck. We propose a specific way of implementing the sampler that allows for optimal resource utilization through minimizing the idle time on the rollout workers.
First, note that training and experience collection are decoupled, so new environment transitions can be collected during the backpropagation step. There are no parameter updates for the rollout workers either, since the job of action generation is off-loaded to the policy worker. However, if not addressed, this still leaves the rollout workers waiting for the actions to be generated by policy workers and transferred back through interprocess communication.
To alleviate this inefficiency we use Double-Buffered Sampling. As illustrated in Fthe following figure: a) Batched sampling enables forward pass acceleration on GPU, but rollout workers have to wait for actions before the next environment step can be simulated, underutilizing the CPU. b) Double-buffered sampling splits k environments on the rollout worker into two groups, alternating between them during sampling, which practically eliminates idle time on CPU workers.
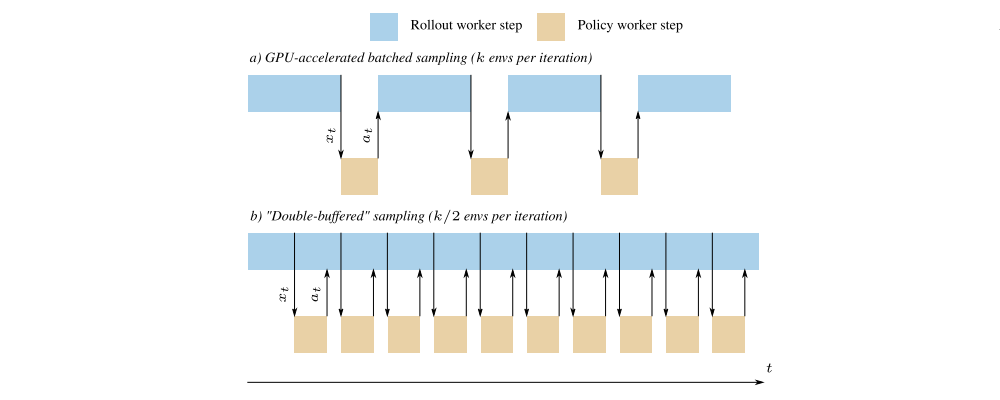
Timeline diagram of double-buffered sampling
Instead of storing only a single environment on the rollout worker, we instead store a vector of environments E1, …, Ek, where k is even for simplicity. We split this vector into two groups E1, …, Ek/2, Ek/2+1, …, Ek, and alternate between them as we go through the rollout. While the first group of environments is being stepped through, the actions for the second group are calculated on the policy worker, and vice versa(反之亦然). With a fast enough policy worker and a correctly tuned value for k we can completely mask the communication overhead and ensure full utilization of the CPU cores during sampling. For maximal performance with double-buffered sampling we want
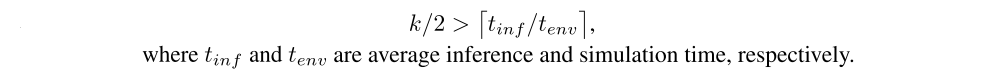
3.3 Communication between components
The key to unlocking the full potential of the local, single-machine setup is to utilize fast communication mechanisms between system components. There are four main pathways for information flow: two-way communication between rollout and policy workers, transfer of complete trajectories to the learner, and transfer of parameter updates from the learner to the policy worker. For the first three interactions we use a mechanism based on PyTorch shared memory tensors. We note that most data structures used in an RL algorithm can be represented as tensors of fixed shape, whether they are trajectories, observations, or hidden states. Thus we preallocate a sufficient number of tensors in system RAM. Whenever a component needs to communicate, we copy the data into the shared tensors, and send only the indices of these tensors through FIFO queues, making messages tiny compared to the overall amount of data transferred.
For the parameter updates we use memory sharing on the GPU. Whenever a model update is required, the policy worker simply copies the weights from the shared memory to its local copy of the model.
Unlike many popular asynchronous and distributed implementations, we do not perform any kind of data serialization as a part of the communication protocol. At full throttle, Sample Factory generates and consumes more than 1 GB of data per second, and even the fastest serialization/deserialization mechanism would severely hinder throughput.
3.4 Policy lag
Policy lag(延迟)is an inherent property of asynchronous RL algorithms, a discrepancy between the policy that collected the experience (behavior policy) and the target policy that is learned from it. The existence of this discrepancy conditions the off-policy training regime. Off-policy learning is known to be hard for policy gradient methods, in which the model parameters are usually updated in the direction of
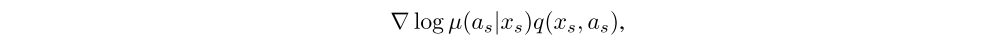
The bigger the policy lag, the harder it is to correctly estimate this gradient using a set of samples xs from the behavior policy. Empirically this gets more difficult in learning problems that involve recurrent policies, high-dimensional observations, and complex action spaces, in which even very similar policies are unlikely to exhibit the same performance over a long trajectory.
Policy lag in an asynchronous RL method can be caused either by acting in the environment using an old policy, or collecting more trajectories from parallel environments in one iteration than the learner can ingest in a single minibatch, resulting in a portion of the experience becoming off-policy by the time it is processed. We deal with the first issue by immediately updating the model on policy workers, as soon as new parameters become available. In Sample Factory the parameter updates are cheap because the model is stored in shared memory. A typical update takes less than 1 ms, therefore we collect a very minimal amount of experience with a policy that is different from the “master” copy.
It is however not necessarily possible to eliminate the second cause. It is beneficial in RL to collect training data from many environment instances in parallel. Not only does this decorrelate the experiences, it also allows us to utilize multi-core CPUs, and with larger values for k (environments per core), take full advantage of the double-buffered sampler. In one “iteration” of experience collection, n rollout workers, each running k environments, will produce a total of Niter = n × k × T samples. Since we update the policy workers immediately after the learner step, potentially in the middle of a trajectory, this leads to the earliest samples in trajectories lagging behind Niter/Nbatch − 1 policy updates on average, while the newest samples have no lag.
One can minimize the policy lag by decreasing T or increasing the minibatch size Nbatch. Both have implications for learning. We generally want larger T, in the 25–27 range for backpropagation through time with recurrent policies, and large minibatches may reduce sample efficiency. The optimal batch size depends on the particular environment, and larger batches were shown to be suitable for complex problems with noisy gradients.
Additionally, there are two major classes of techniques designed to cope with off-policy learning.
-
The first idea is to
apply trust region methods: by staying close to the behavior policy during learning, we improve the quality of gradient estimates obtained using samples from this policy. -
Another approach is to
use importance samplingto correct the targets for the value function Vπ to improve the approximation of the discounted sum of rewards under the target policy. IMPALA introduced the V-trace algorithm that uses truncated importance sampling weights to correct the value targets. This was shown to improve the stability and sample-efficiency of off-policy learning.