Tiny Project 1: Using Reinforcement Learning to Trade Stocks
Github: https://github.com/Kiiiiii123/TradeWithRL.
Introduction
As mentioned in previous blogs, stock exchange market is an excellent environment for reinforcement learning research. However, this tiny project is just for fun… 😂
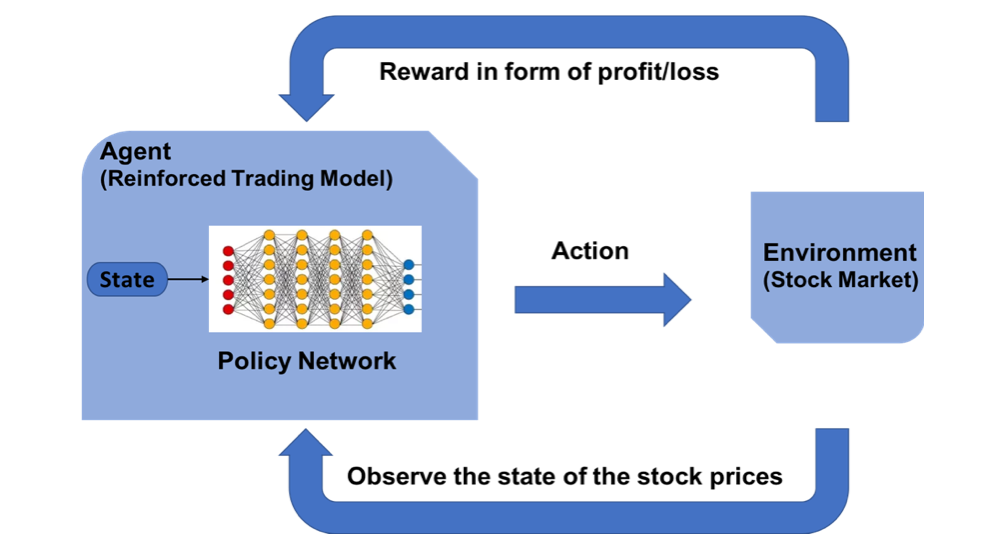
OpenAI Gym Stock Trading Environment
We implement the env.StockTradingEnv class in CustomEnv.py, inheriting from gym.Env class.
-
Observation Space
Our trading strategy observes the parameters of every stock, such as opening price, closing price, volume, etc. Since some parameters have large values, to guarantee the convergence of network training, the observation values must be normalized into [-1, 1].
| Parameters | Description | Details |
|---|---|---|
| date | trading date | Format: YYYY-MM-DD |
| code | stock code | Format: sh.600000; sh: Shanghai; sz: Shenzhen |
| open | opening price | Accuracy: 4 decimal places; Unit: yuan |
| high | top price | Accuracy: 4 decimal places; Unit: yuan |
| low | minimum price | Accuracy: 4 decimal places; Unit: yuan |
| close | closing price | Accuracy: 4 decimal places; Unit: yuan |
| preclose | closing price yday | Accuracy: 4 decimal places; Unit: yuan |
| volume | volume of trade | Unit: share |
| amount | stock turnover | Accuracy: 4 decimal places; Unit: yuan |
| adjustflag | adjust status | no adjust, forward adjust, backward adjust |
| turn | turnover rate (%) | Accuracy: 6 decimal places |
| tradestatus | stock trading status | 1: normal trading; 0: suspended |
| pctChg | change (%) | Accuracy: 6 decimal places |
| peTTM | rolling price-earnings ratio | Accuracy: 6 decimal places |
| psTTM | rolling price-sales ratio | Accuracy: 6 decimal places |
| pcfNcfTTM | rolling price-cash ratio | Accuracy: 6 decimal places |
| pbMRQ | P/B ratio | Accuracy: 6 decimal places |
-
Action Space
We assume that there are only three operations to choose from: buy, sell and hold. We define the action as an array of length 2. The discrete value of action[0] represents different stock operations, the continuous value of action[1] represents a buy or sell percentage.
| action[0] | Description |
|---|---|
| 1 | buy: action[1] |
| 2 | sell: action[1] |
| 3 | hold |
Note that when action[0] = 3, our trading strategy will not buy nor sell stock, meanwhile, the value of action[1] is meaningless. Our trading agent learns about this during the training process.
-
Reward Function
When trained in a stock trading environment, the strategy is most concerned with its current profitability, so we use the current profit as our reward function.
self.net_worth = self.balance + self.shares_held * current_price
# profit
reward = self.net_worth - INITIAL_ACCOUNT_BALANCE
reward = 1 if reward > 0 else reward = -100
In order to accelerate the training process of our strategy network and get a profitable strategy, when the profit is negative, a large penalty is given to the network (-100).
Trading Strategy
Since the action[1] value is continuous, PPO, the optimization algorithm based on policy-gradient is used. We just use the python implementation in stable-baselines.
Experiment
-
Installation
# create and active virtual environment
virtualenv -p python3.6 venv
source ./venv/bin/activate
# dependencies
pip install -r requirements.txt
-
Dataset
Our stock data comes from baostock, a free and open-source stock data platform. We can download stock data (pandas DataFrame) through its python API.
>> pip install baostock -i https://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host pypi.tuna.tsinghua.edu.cn
>> python get_stock_data.py
In get_stock_data.py, the stock data of the past 20 years were divided into training set and the data of the last month as the test set. The test set is necessary for verifying the effectiveness of our reinforcement learning strategy.
| 1990-01-01 ~ 2019-11-29 | 2019-12-01 ~ 2019-12-31 |
|---|---|
| training set | test set |
Results
-
Single-Stock
-
Initial Balance: 10000
-
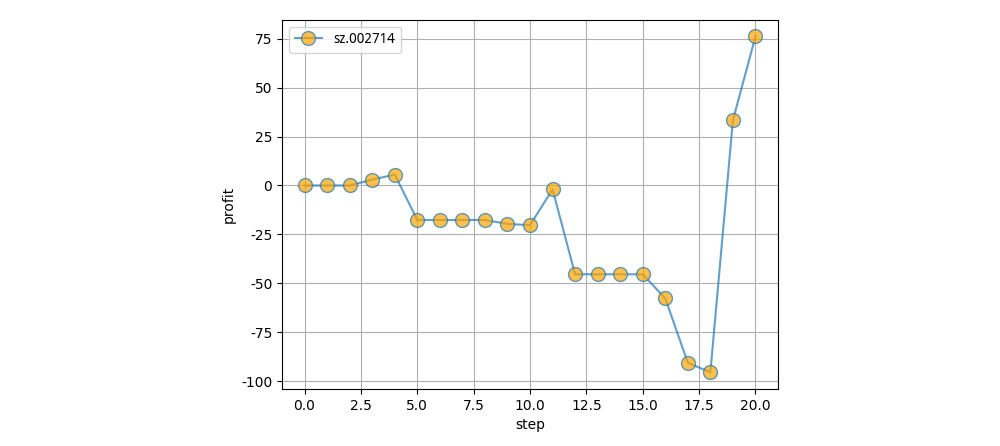
Stock Code: sz.002714 (Muyuan Food stuff Co,Ltd)
-
Training Set: stockdata/train/sz.002714.牧原股份.csv
-
Test Set: stockdata/test/sz.002714.牧原股份.csv
-
Simulate 20 days, the final profit of about 75
-
-
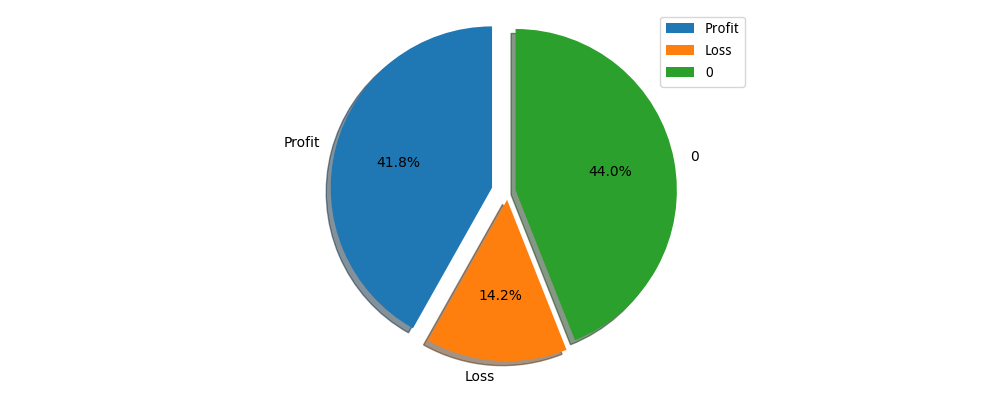
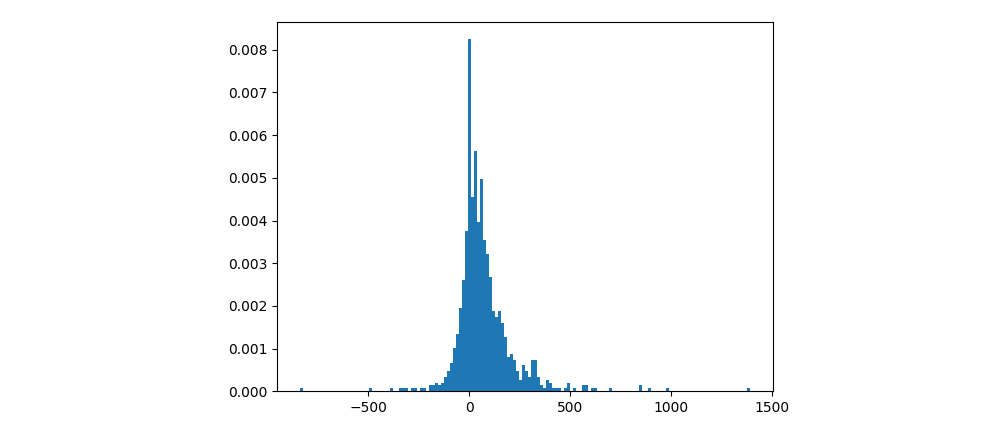
Multi-Stock
We choose 1002 stocks and train the trading strategies with the training data. Run visualize_bacth_testing.py, then we can get the backtesting result of our strategies as below: